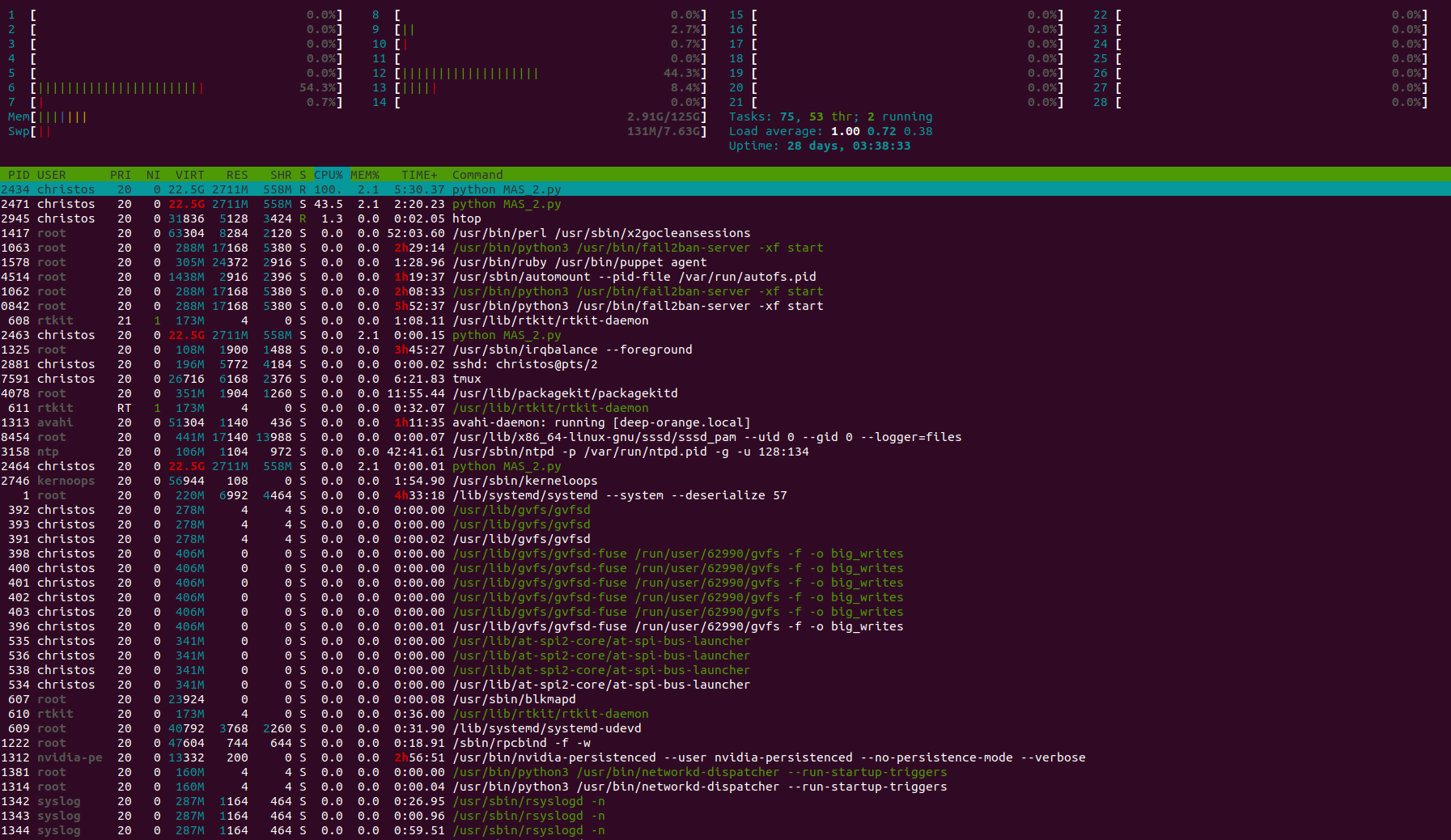
I am trying to run a 2-agent grid-world-based training, using the GPU. However, training is very slow (optimize() function in the code that I attach) and when I run nvidia-smi I see only around 15% GPU usage. Also, htop shows CPU usage (I attach a pic).
Is this normal?
When I do the same with just a single-agent it’s around 10 times faster. Of course, in that case the network has 5 outputs whereas in the 2-agent case it’s two networks with 25 outputs each, but does that explain the huge difference in time?
In the single-agent case I get a bit more GPU (around 25%) but still a lot of CPU.
import math
import random
import numpy as np
from tqdm import tqdm
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple
from itertools import count
from PIL import Image
import time
import pickle
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as T
import cv2
# set up matplotlib
is_ipython = 'inline' in matplotlib.get_backend()
if is_ipython:
from IPython import display
AGGREGATE_STATS_EVERY = 50 # episodes
SHOW_EVERY = 2500
device = torch.device("cuda:0")
Transition = namedtuple('Transition',
('state', 'action', 'next_state', 'reward','done'))
class Blob:
def __init__(self, size):
self.size = size
self.x = torch.randint(0,size,(1,),device=device)
self.y = torch.randint(0,size,(1,),device=device)
def __str__(self):
return f"Blob ({self.x}, {self.y})"
def __sub__(self, other):
return (self.x-other.x, self.y-other.y)
def __eq__(self, other):
return self.x == other.x and self.y == other.y
def action(self, choice):
'''
Gives us 5 total movement options. (0,1,2,3,4)
'''
if choice == 0:
self.move(x=1, y=0) #LEFT
elif choice == 1:
self.move(x=-1, y=0) #RIGHT
elif choice == 2:
self.move(x=0, y=1) #NORTH
elif choice == 3:
self.move(x=0, y=-1) #SOUTH
elif choice == 4:
self.move(x=0, y=0) #NOTHING
def move(self, x=None, y=None):
# If no value for x, move randomly
if x==None:
self.x += torch.randint(-1,2,(1,),device=device)
else:
self.x += x
# If no value for y, move randomly
if y==None:
self.y += torch.randint(-1,2,device=device) #np.random.randint(-1, 2)
else:
self.y += y
# If we are out of bounds, fix!
if self.x < 0:
self.x = 0
elif self.x > self.size-1:
self.x = self.size-1
if self.y < 0:
self.y = 0
elif self.y > self.size-1:
self.y = self.size-1
class BlobEnv:
#def __init__(self, NP):
SIZE = 10
RETURN_IMAGES = True
MOVE_PENALTY = 1
MOVE_PENALTY = torch.Tensor([MOVE_PENALTY]).to(device)
ENEMY_PENALTY = 300
ENEMY_PENALTY = torch.Tensor([ENEMY_PENALTY]).to(device)
FOOD_REWARD = 25
FOOD_REWARD = torch.Tensor([FOOD_REWARD]).to(device)
OBSERVATION_SPACE_VALUES = (SIZE,SIZE, 3) # 4
ACTION_SPACE_SIZE = 5 #9
foods = []
enemies = []
players = []
NUMBER_OF_ENEMIES = 3
NUMBER_OF_PLAYERS = 2
taken = [0,0]
# the dict! (colors) in RGB
# player 1, player 2, ..., food1, food2,..., enemies
d = {1: (255, 0, 0),
2: (200, 0, 0),
3: (0, 255, 0),
4: (0, 200, 0)}
def reset(self):
kk = 0
for i in range(self.NUMBER_OF_PLAYERS):
food = Blob(self.SIZE)
food.x = kk
food.y = kk
self.foods.append(food)
kk += 4
enemy = Blob(self.SIZE)
enemy.x = 1
enemy.y = 1
self.enemies.append(enemy)
enemy = Blob(self.SIZE)
enemy.x = 5
enemy.y = 5
self.enemies.append(enemy)
self.enemies.append(enemy)
enemy = Blob(self.SIZE)
enemy.x = 9
enemy.y = 9
self.enemies.append(enemy)
for i in range(self.NUMBER_OF_PLAYERS):
player = Blob(self.SIZE)
self.players.append(player)
for i in range(self.NUMBER_OF_PLAYERS):
while self.players[i] == self.enemies[0] or self.players[i] == self.enemies[1] or self.players[i] == self.enemies[2] or self.players[i] == self.foods[0] or self.players[i] == self.foods[1]:
self.players[i] = Blob(self.SIZE)
self.episode_step = 0
if self.RETURN_IMAGES:
env, img = self.get_image()
observation = env
else:
observation = (self.player-self.food) + (self.player-self.enemy)
return observation
def step(self, actions):
self.episode_step += 1
for i in range(self.NUMBER_OF_PLAYERS):
self.players[i].action(actions[i])
if self.RETURN_IMAGES:
env,img = self.get_image()
new_observation = env
else:
new_observation = (self.player-self.food) + (self.player-self.enemy)
rewards = [0,0]
hit_enemy = [0,0]
hit_food = [0,0]
done_sep = [0,0]
for i in range(self.NUMBER_OF_PLAYERS):
for j in range(self.NUMBER_OF_ENEMIES):
if self.players[i].x == self.enemies[j].x and self.players[i].y == self.enemies[j].y:
cur_reward = -self.ENEMY_PENALTY
hit_enemy[i] = 1
done_sep[i] = 1
break
if not hit_enemy[i]:
for j in range(self.NUMBER_OF_PLAYERS):
if self.players[i].x == self.foods[j].x and self.players[i].y == self.foods[j].y and not self.taken[j]:
cur_reward = self.FOOD_REWARD
self.taken[j] = 1
done_sep[i] = 1
hit_food[i] = 1
break
if not hit_food[i]:
cur_reward = -self.MOVE_PENALTY
rewards[i] = cur_reward
done = torch.Tensor([False]).to(device)
if all(done_sep) or self.episode_step >= 200:
done = torch.Tensor([True]).to(device)
return new_observation, rewards, done
def render(self):
img = self.get_image()
img = img.resize((300, 300)) # resizing so we can see our agent in all its glory.
cv2.imshow("image", np.array(img)) # show it!
cv2.waitKey(1)
# FOR CNN #
def get_image(self):
env = np.zeros((self.SIZE, self.SIZE, 3), dtype=np.uint8) # starts an rbg of our size
env2 = torch.zeros((3,self.SIZE,self.SIZE), device=device)
for i in range(self.NUMBER_OF_ENEMIES):
env2[2,self.enemies[i].x,self.enemies[i].y] = 255
for i in range(self.NUMBER_OF_PLAYERS):
env2[0,self.players[i].x,self.players[i].y] = self.d[i+1][0]
env2[1,self.players[i].x,self.players[i].y] = self.d[i+1][1]
env2[2,self.players[i].x,self.players[i].y] = self.d[i+1][2]
env2[0,self.foods[i].x,self.foods[i].y] = self.d[i + self.NUMBER_OF_PLAYERS + 1][0]
env2[1,self.foods[i].x,self.foods[i].y] = self.d[i + self.NUMBER_OF_PLAYERS + 1][1]
env2[2,self.foods[i].x,self.foods[i].y] = self.d[i + self.NUMBER_OF_PLAYERS + 1][2]
img = Image.fromarray(env, 'RGB') # reading to rgb. Apparently. Even tho color definitions are bgr. ???
return env2, img
class ReplayMemory(object):
def __init__(self, capacity):
self.capacity = capacity
self.memory = []
self.position = 0
def push(self, *args):
"""Saves a transition."""
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.position] = Transition(*args)
self.position = (self.position + 1) % self.capacity
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
#return list(self.memory)[-batch_size:]
def __len__(self):
return len(self.memory)
class Flatten(nn.Module):
def forward(self, x):
N, C, H, W = x.size() # read in N, C, H, W
return x.view(N, -1)
class DQN(nn.Module):
def __init__(self, h, w, outputs):
super(DQN, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 256, kernel_size=3, stride=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Dropout(p=0.2),
nn.Conv2d(256, 256, kernel_size=3, stride=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Dropout(p=0.2),
Flatten(),
nn.Linear(256, 64),
nn.Linear(64, outputs),
)
def forward(self, x):
return self.model(x)
resize = T.Compose([T.ToPILImage(),
T.Resize(40, interpolation=Image.CUBIC),
T.ToTensor()])
env = BlobEnv()
BATCH_SIZE = 64
GAMMA = 0.99
EPS_START = 1
eps_threshold = EPS_START
EPS_END = 0.001
EPS_DECAY = 200
EPSILON_DECAY = 0.99975
TARGET_UPDATE = 5
REPLAY_MEMORY_SIZE = 50_000
MIN_REPLAY_MEMORY_SIZE = 1_000
NUM_PLAYERS = 2
ACTION_SPACE_SIZE = env.ACTION_SPACE_SIZE
# Get number of actions from gym action space
n_actions = env.ACTION_SPACE_SIZE**NUM_PLAYERS #so for 2 players and 5 actions it will be 5^2 = 25
policy_net1 = DQN(env.SIZE, env.SIZE, n_actions).to(device)
target_net1 = DQN(env.SIZE, env.SIZE, n_actions).to(device)
target_net1.load_state_dict(policy_net1.state_dict())
target_net1.eval()
policy_net2 = DQN(env.SIZE, env.SIZE, n_actions).to(device)
target_net2 = DQN(env.SIZE, env.SIZE, n_actions).to(device)
target_net2.load_state_dict(policy_net2.state_dict())
target_net2.eval()
policy_nets = [policy_net1,policy_net2]
target_nets = [target_net1,target_net2]
optimizer1 = optim.Adam(policy_net1.parameters(),lr=0.001,eps=1e-07)
optimizer2 = optim.Adam(policy_net2.parameters(),lr=0.001,eps=1e-07)
optimizers = [optimizer1,optimizer2]
memory1 = ReplayMemory(REPLAY_MEMORY_SIZE)
memory2 = ReplayMemory(REPLAY_MEMORY_SIZE)
memories = [memory1,memory2]
steps_done = 0
def select_action(policy_net,state,ep_steps):
global steps_done
global eps_threshold
sample = random.random()
#eps_threshold = EPS_END + (EPS_START - EPS_END) * \
# math.exp(-1. * steps_done / EPS_DECAY)
#steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
# t.max(1) will return largest column value of each row.
# second column on max result is index of where max element was
# found, so we pick action with the larger expected reward.
return policy_net(state).max(1)[1].view(1, 1), 0
else:
#print('RAND')
return torch.tensor([[random.randrange(ACTION_SPACE_SIZE)]], device=device, dtype=torch.long), 1
episode_durations = []
def optimize_model():
global ep_loss
for i in range(NUM_PLAYERS):
if len(memories[i]) < MIN_REPLAY_MEMORY_SIZE: #BATCH_SIZE:
return
transitions = memories[i].sample(BATCH_SIZE)
# Transpose the batch (see https://stackoverflow.com/a/19343/3343043 for
# detailed explanation). This converts batch-array of Transitions
# to Transition of batch-arrays.
batch = Transition(*zip(*transitions))
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
done_batch = torch.cat(batch.done)
next_state_batch = torch.cat(batch.next_state)
# Compute Q(s_t, a) - the model computes Q(s_t), then we select the
# columns of actions taken. These are the actions which would've been taken
# for each batch state according to policy_net
policy_net = policy_nets[i]
target_net = target_nets[i]
state_action_values = policy_net(state_batch).gather(1, action_batch)
state_action_values_from_others = torch.zeros([BATCH_SIZE,1], device=device)
for j in range(NUM_PLAYERS):
if i == j:
continue
state_action_values_from_others += policy_nets[j](state_batch).gather(1, action_batch)
expected_state_action_values = torch.zeros(BATCH_SIZE, device=device)
next_state_max_values = target_net(next_state_batch).max(1)[0].detach()
# Compute the expected Q values
for index in range(BATCH_SIZE):
if not done_batch[index]:
expected_state_action_values[index] = next_state_max_values[index]*GAMMA + reward_batch[index] + \
state_action_values_from_others[index]
else:
expected_state_action_values[index] = reward_batch[index]
loss = F.mse_loss(state_action_values, expected_state_action_values.unsqueeze(1))
ep_loss += loss
# Optimize the model
optimizers[i].zero_grad()
loss.backward()
for param in policy_net.parameters():
param.grad.data.clamp_(-1, 1)
#start = time.time()
optimizers[i].step()
#print('time = ', time.time()-start)
ep_rewards = [-200]
avg_reward_list = []
average_reward_list = []
times_enemy_list = []
times_food_list = []
avg_opt_times_list = []
ep_loss_list = []
num_episodes = 20_000
for i_episode in tqdm(range(num_episodes)):
state = env.reset()
episode_reward = 0
times_enemy = 0
times_food = 0
ep_steps = 0
ep_loss = 0
for t in count():
# Select and perform an action
state_torch = state.view(-1,3,env.SIZE,env.SIZE)
actions = torch.zeros( (NUM_PLAYERS,1,1), dtype=torch.long, device=device)
for i in range(NUM_PLAYERS):
cur_act, rand = select_action(policy_nets[i],state_torch,ep_steps)
if not rand: #then we must decode
action_1 = torch.floor_divide(cur_act, ACTION_SPACE_SIZE)
action_2 = cur_act - ACTION_SPACE_SIZE*action_1
#make this better
if i==0:
actions[i] = action_1
else:
actions[i] = action_2
else:
actions[i] = cur_act
#need to encode "actions" to 0...n_actions (0...25)
#for 2 agents:
action_stack = ACTION_SPACE_SIZE * actions[0] + actions[1]
next_state, rewards, done = env.step(actions)
episode_reward += sum(rewards)
next_state_torch = next_state.view(-1,3,env.SIZE,env.SIZE)
# Store the transition in memory
for i in range(NUM_PLAYERS):
memories[i].push(state_torch/255, action_stack, next_state_torch/255, rewards[i], done)
# Move to the next state
state = next_state
ep_steps += 1
# Perform one step of the optimization (on the target network)
#start = time.time()
optimize_model()
#print(time.time() - start)
if done:
ep_rewards.append(episode_reward)
episode_durations.append(t + 1)
if eps_threshold > EPS_END:
eps_threshold *= EPSILON_DECAY
eps_thresold = max(EPS_END,eps_threshold)
if not i_episode % SHOW_EVERY:
with open('data_'+str(i_episode)+'.pkl', 'wb') as f:
pickle.dump(avg_reward_list,f)
if not i_episode % AGGREGATE_STATS_EVERY:
average_reward = sum(ep_rewards[-AGGREGATE_STATS_EVERY:])/len(ep_rewards[-AGGREGATE_STATS_EVERY:])
avg_reward_list.append(average_reward)
break
# Update the target network, copying all weights and biases in DQN
if i_episode % TARGET_UPDATE == 0:
target_net1.load_state_dict(policy_net1.state_dict())
target_net2.load_state_dict(policy_net2.state_dict())