hello all
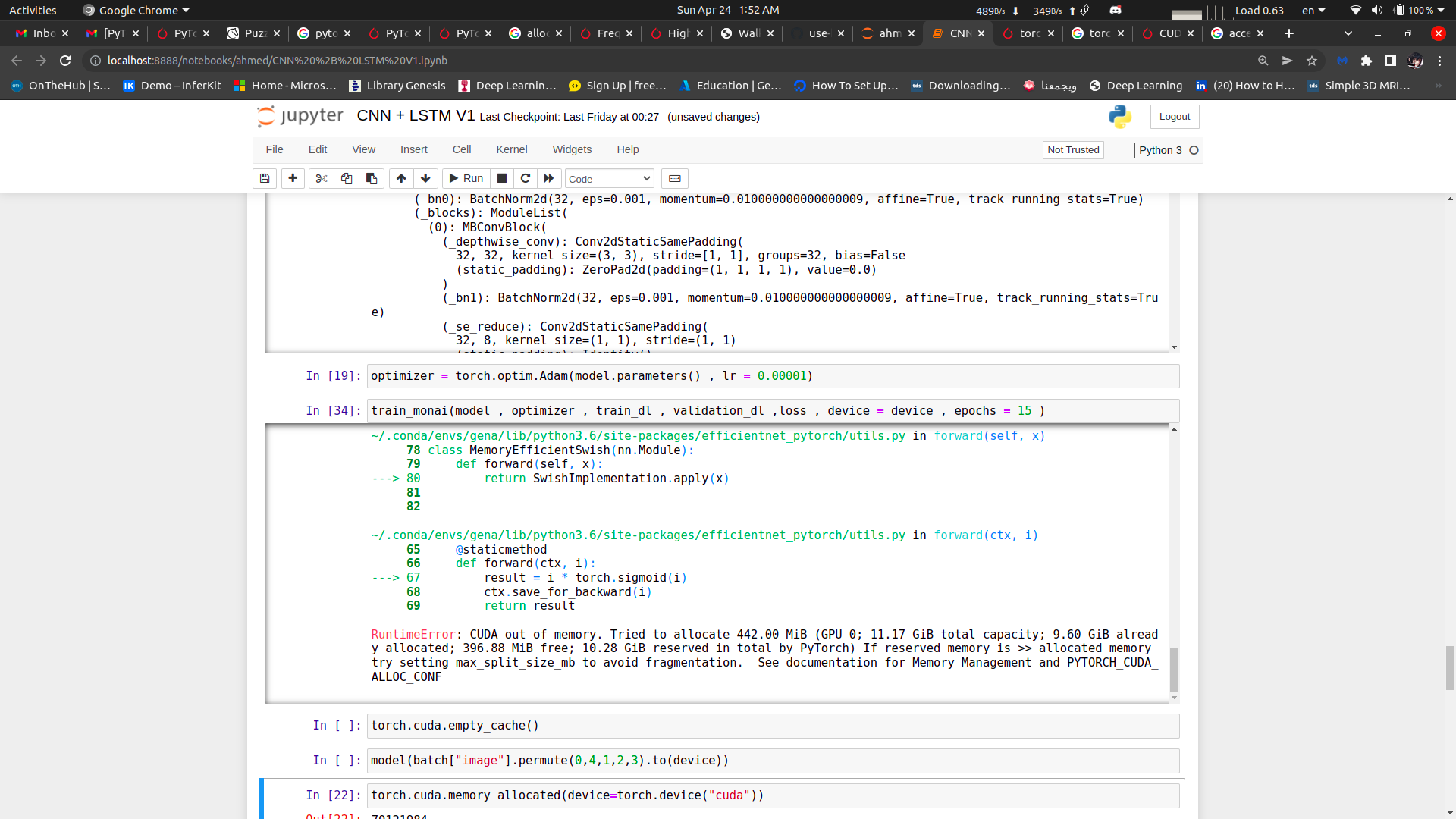
I am training a CNN - LSTM model and every time I try to run the training I always get the following cuda error , I am working on hpc server which have two GPU and using nn.DataParrallel(model) , doesn’t seem to change anything , so I need some help please
You are running out of memory, so you would either need to reduce the memory requirement e.g. by lowering the batch size, or you could trade compute for memory via torch.utils.checkpoint.
The memory requirement depend on the used model as well as the input shape. Dont forget that during training the intermediate forward activations, the gradients, and the optimizer’s states (if available) will use additional memory.
If i understand your question correctly, the input size is 4x3x64×224×224?
That’s essentially 256 RGB images of size 224x224. I do not know the type of model you are using. But i would imagine, for a model like ResNet, this input size is already huge for forward pass in a ~11GB GPU. Try reducing the number of images in the sequence or batch size or spatial size of the image.
it is grey scale not rgb + I changed the spatial size to 64 and the batch to 2 and still doesn’t fit , I use efficient net as an encoder before the LSTM
I haven’t used EfficientNet a lot. I’m not sure about it’s memory requirements.
I would try to reduce the number of images in the sequence as far as possible to get a lowest baseline. Then, start from the lowest possible baseline and try to increase the dimensions (batch size, spatial size or number of images in a sequence) one by one to see what’s the maximum limit that can be used in your GPU.