i assume since the code runs fine with num_workers>0 for both cpu and single gpu, then my collate function is serializable. is that not always the case?
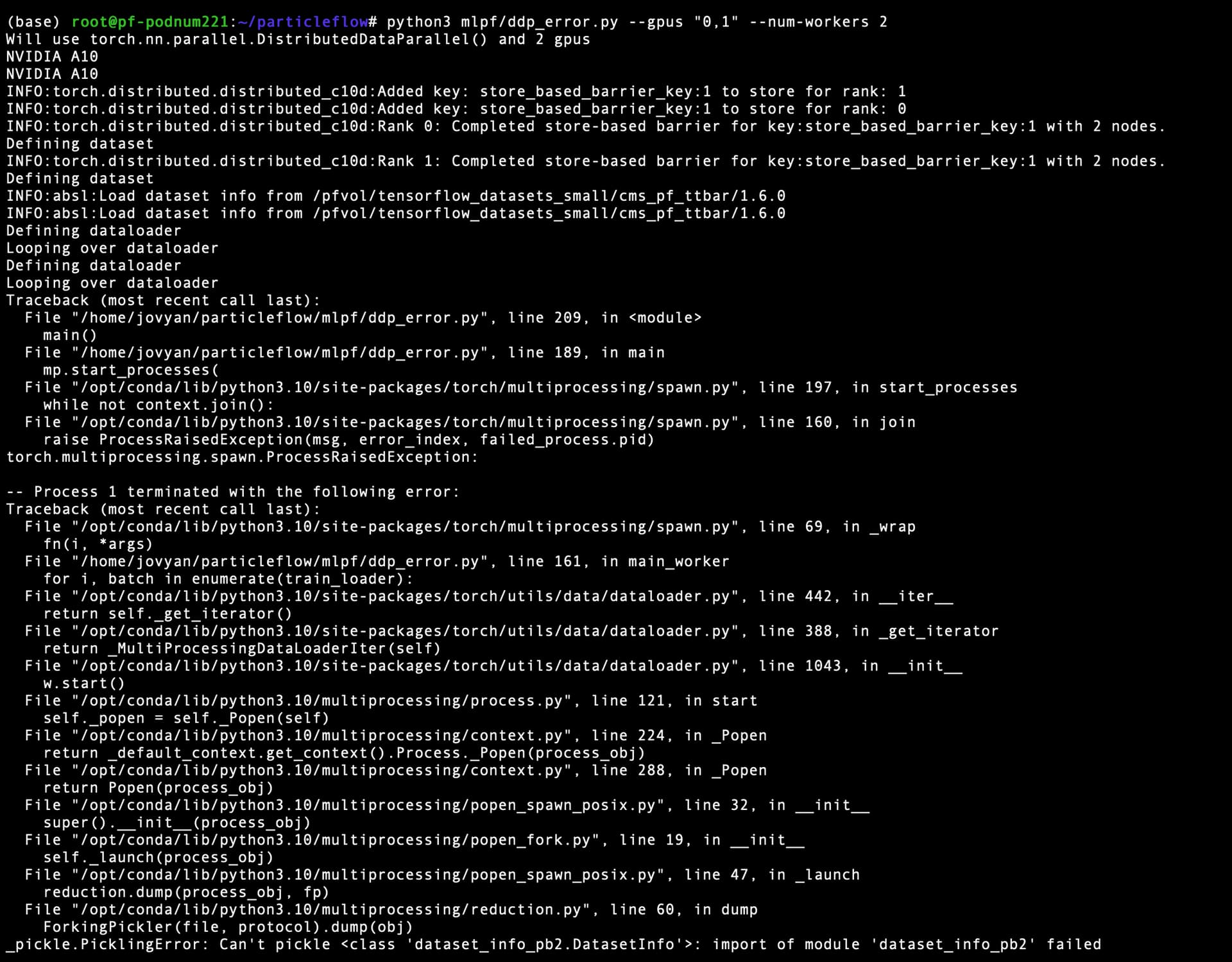
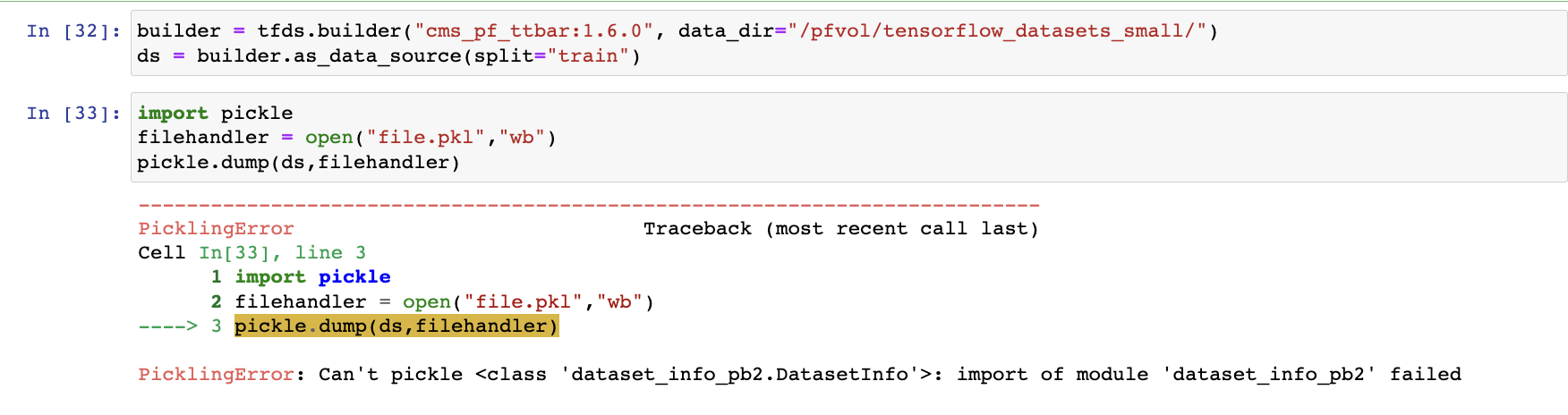
ok it seems that my datasource cannot be serialized. is there a way around that? and do you happen to know why the code works fine with torch distributed expect when num_workers>0
This is more of a mechanism of the dataloader rather than any distributed code, see the mulitprocess section of dataloader torch.utils.data — PyTorch 2.1 documentation or you can try asking for help in that topic of the forum data - PyTorch Forums. My understanding is that when num_workers > 0 each worker process will pickle the dataset when it has to create an instance of the dataloader, my guess is this is to prevent multiple instatiations on the dataset across multiple processes.
thanks alot for the help! your references helped alot!!
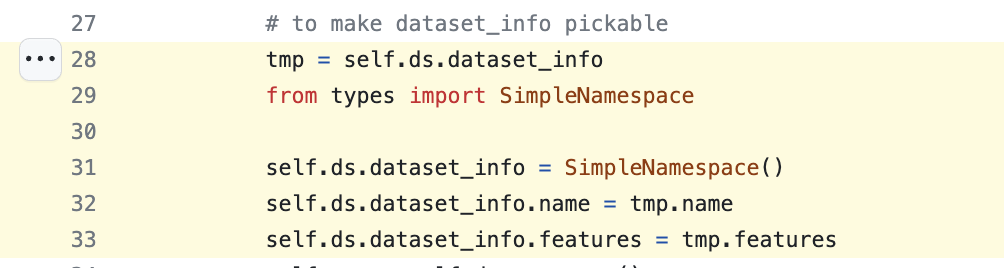
I managed to solve it by defining this part to avoid pickling the dataset_info class and just pickle a SimpleNamespace that holds the content the dataloader would need from dataset_info