This is not an error, as you can see:
0 53448 C /opt/conda/bin/python 803MiB
1 53448 C /opt/conda/bin/python 1511MiB
Their PID are the same, it seems that DDP will spawn an additional process for all “secondary processes”, except the “primary process”, probably for receiving tensors etc. “803MiB” should be the base kernel memory usage, if you spawn any process using cuda in pytorch. Actions such as moving a model to gpu, creating a tensor on gpu will invoke cuda. see this issue for detail explainations: issue
I can also replicate this behavior on my machine, so don’t worry about it:
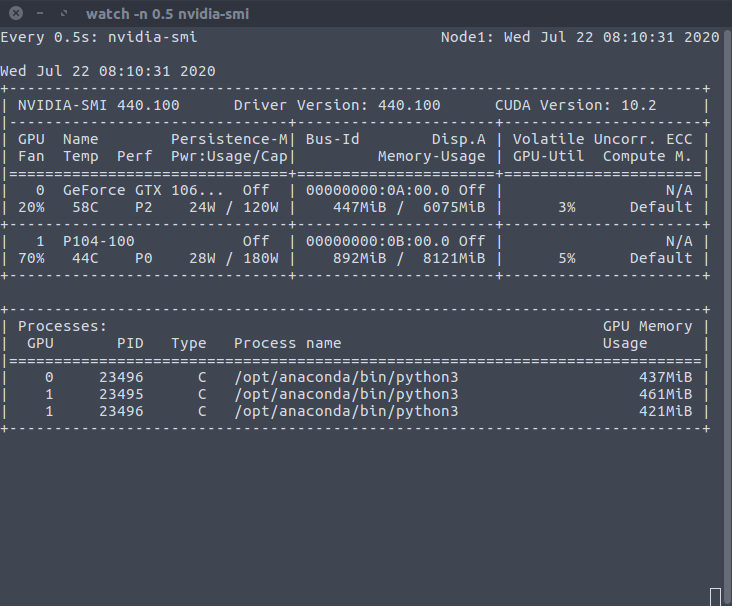
The replication script is a slightly modified version from the DDP tutorial:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
import os
os.environ["MASTER_ADDR"]="localhost"
os.environ["MASTER_PORT"]="9003"
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
while True:
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()