I was analyzing a tracing from one of my experiments. At a given point I have two consecutive aten::flip operations with the respective input dimensions:
[[128, 128, 64, 6], []][[128, 128, 64, 13, 6], []]
This would be the code associated with it
Y = torch.nn.functional.pad(Y, padding)
if Y.ndim == 5:
Y[:, :, :, 0, m:] = _Y[:, :, :, 0, 1:1+p].flip([-1])
Y[:, :, :, 1:, m:] = _Y[:, :, :, 1:, 1:1+p].flip([-2, -1]);
elif Y.ndim == 4:
Y[:, :, 0, m:] = _Y[ :, :, 0, 1:1+p].flip([-1])
Y[:, :, 1:, m:] = _Y[ :, :, 1:, 1:1+p].flip([-2, -1]);
else:
raise ValueError('Wrong Shape for Y')
For some reason the first takes more time to execute than the second. This is counter-intuitive for me given the first has less elements. Why would this be?
Here are some screen shots from the tracing.
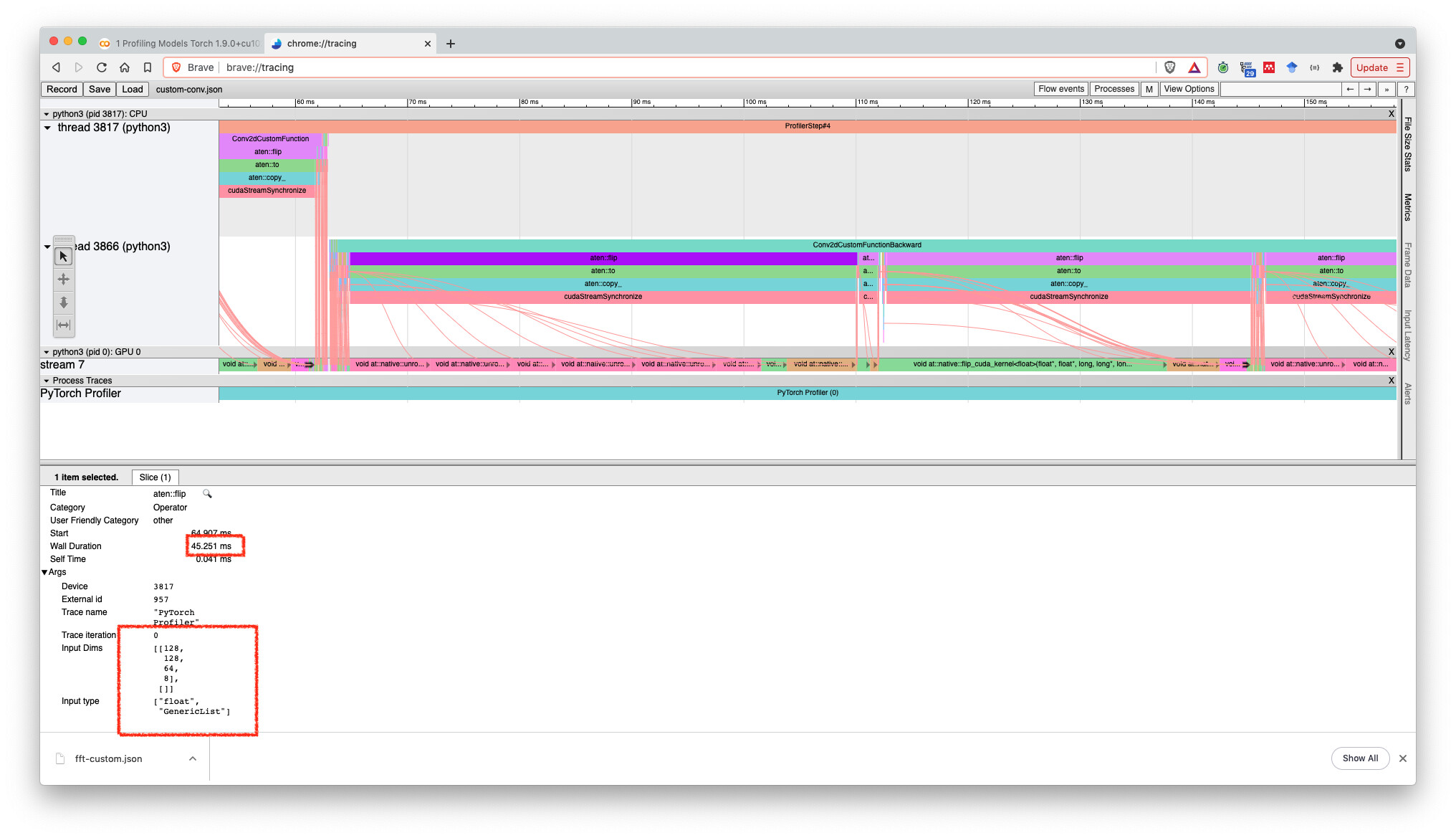
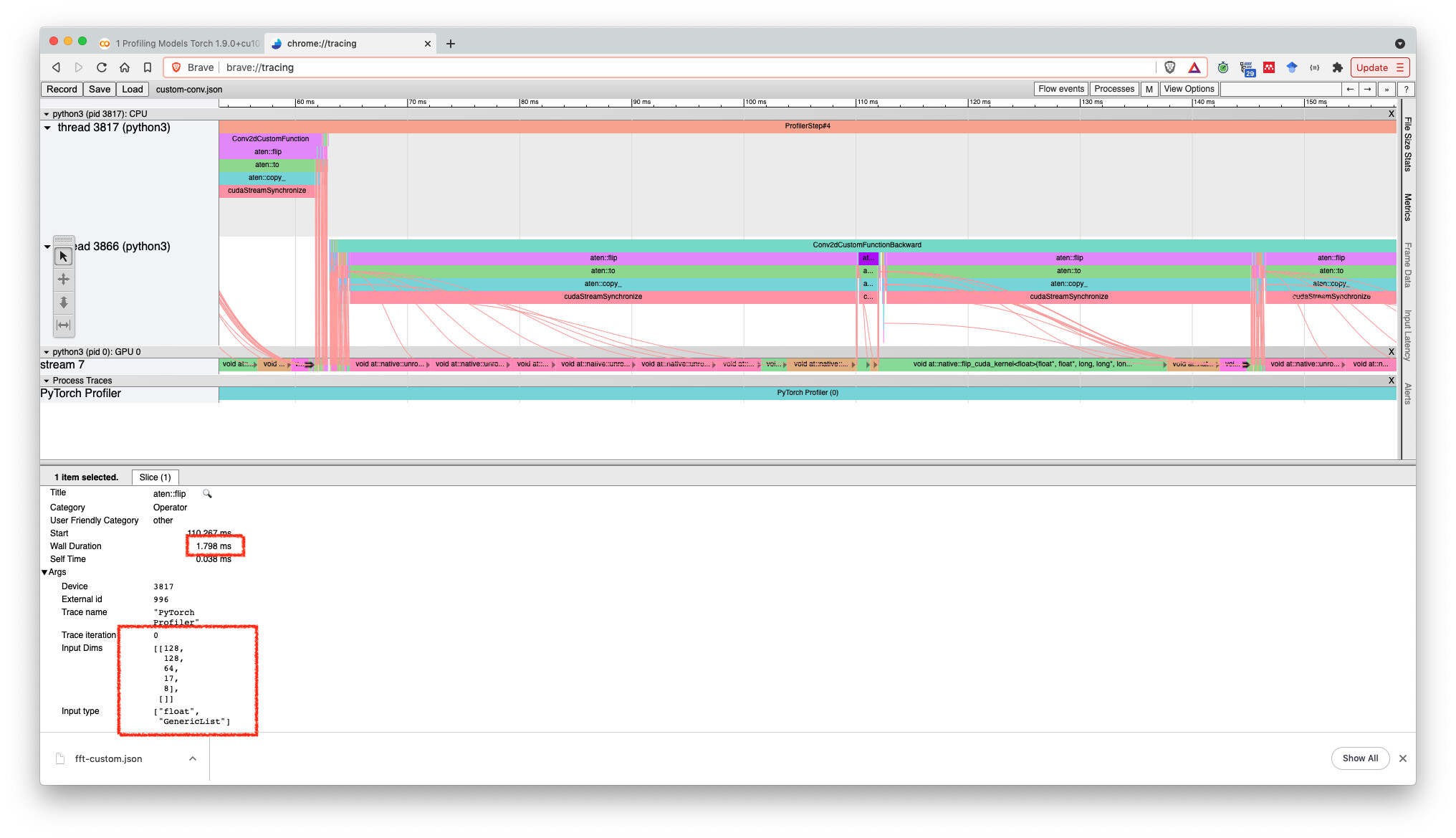
I am pretty new to tracing and understanding all the dynamics of GPU kernel dispatches and optimization. Is there anything I am missing that would make things more clear here?