I am training the MNIST dataset with HOGWILD Async SGD as per your example. I am using a CPU with 64 cores and a GPU A100.
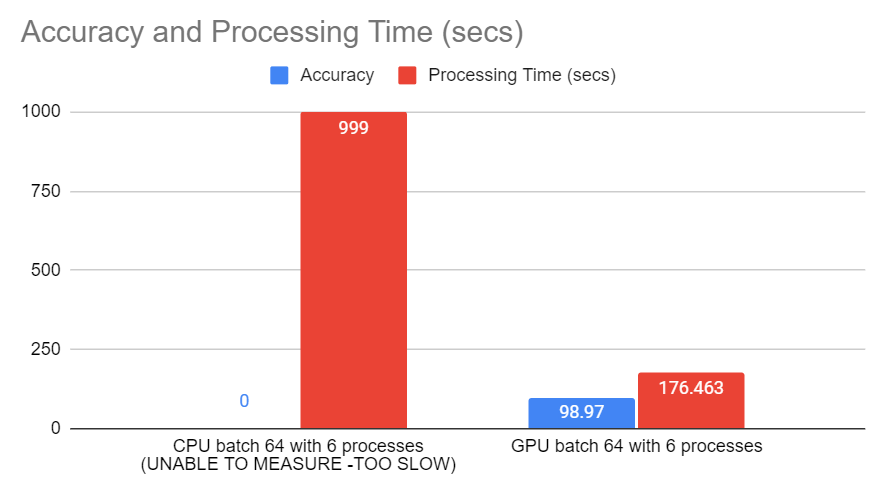
When running the program for CPU, the more processors I use the more time takes to run. I have tried with 3,4,5,6,…and more and the process stalls. As per the figure you can appreciate that when running the program with 6 processes the processing time becomes “infinite” (represented here by 999).I can attest that the number of processes translates to the number of cores used to run the program, because when I monitor the cpu usage I can see that the cores that are busy equals the number of processes specified in the run. I thought that the more processors used the faster the training would be, but is not the case, at first I thought that the communication increased and could be the culprit, but I am not sure, do you know why? Is this a bug, or I am missing something?
Also, for the case of running the program with --cuda, what is the significance of number of processes?, if there is only one GPU available? What I observed is that even though the process does not stall, the processing time grows with the increased number of processors as well.
Thanks for your help.