Hello People,
I am trying to train an off-line reinforcement learning algorithm. The algorithm that I am using follows this paper:
In this algorithm, 4 different neural networks are trained simultaneously, one of them being a Q-function that is approximated by a deep neural network. This is the architecture of my DQN:
class Critic(nn.Module):
def init(self, state_dim, action_dim):
super(Critic, self).init()
self.l1 = nn.Linear(state_dim + action_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, 1)
self.l4 = nn.Linear(state_dim + action_dim, 400)
self.l5 = nn.Linear(400, 300)
self.l6 = nn.Linear(300, 1)
def forward(self, state, action):
q1 = F.relu(self.l1(torch.cat([state, action], 1)))
q1 = F.relu(self.l2(q1))
q1 = self.l3(q1)
return q1
I use adam optimizer to optimize the model parameters:
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=1e-3)
I compute the loss by:
current_Q1, current_Q2 = self.critic(state, action)
critic_loss = F.mse_loss(current_Q1, target_Q)
And I do one step of optimization by:
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
But the critic loss is exploding:
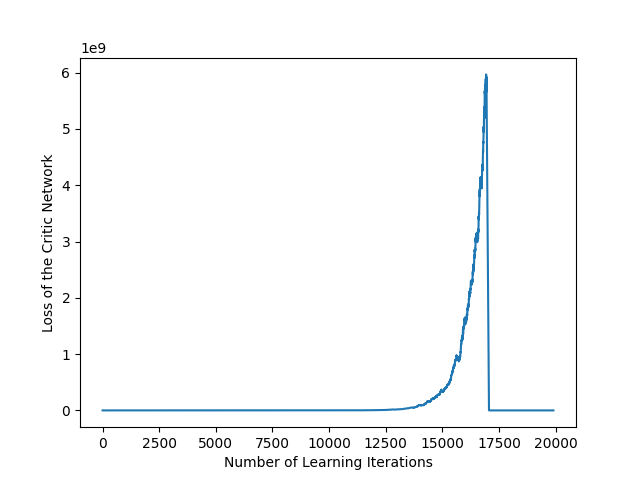
Thanks for your help and support in advance!