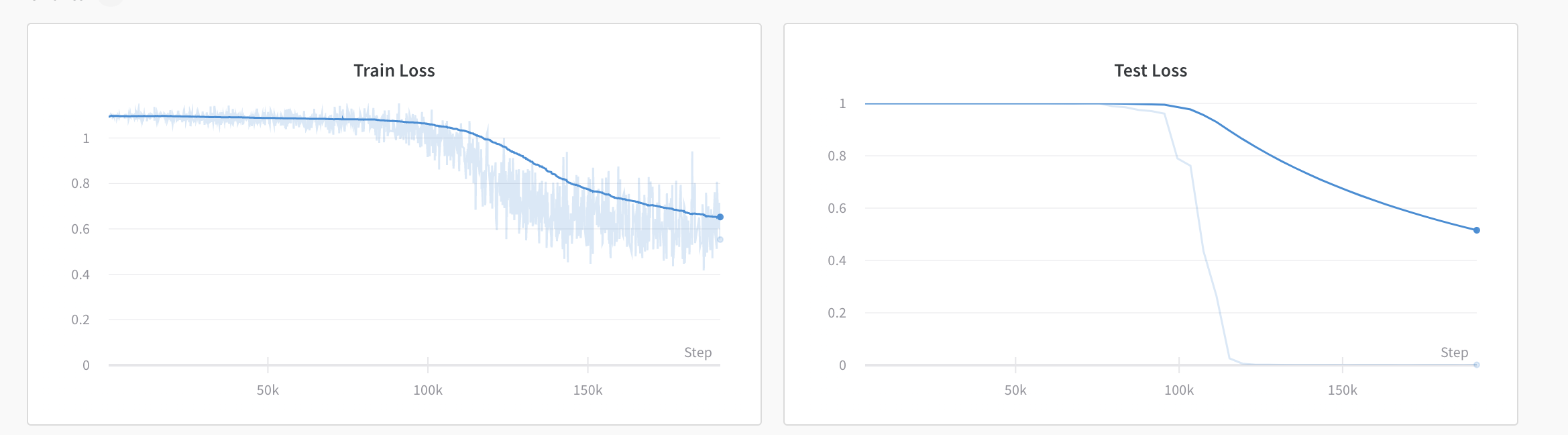
What are some possible causes for the long flat part at the start of training ?
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# input_shape = (64, 100, 40, 1)
## build the convolutional block
self.conv1 = nn.Conv2d(1, 32, (1, 2), stride=(1, 2))
nn.init.xavier_uniform_(self.conv1.weight)
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(32, 32, (4, 1))
nn.init.xavier_uniform_(self.conv2.weight)
self.relu2 = nn.LeakyReLU(0.1)
self.conv3 = nn.Conv2d(32, 32, (4, 1))
nn.init.xavier_uniform_(self.conv3.weight)
self.relu3 = nn.LeakyReLU(0.1)
self.conv4 = nn.Conv2d(32, 32, (1, 2), stride=(1, 2))
nn.init.xavier_uniform_(self.conv4.weight)
self.relu4 = nn.LeakyReLU(0.1)
self.conv5 = nn.Conv2d(32, 32, (4, 1))
nn.init.xavier_uniform_(self.conv5.weight)
self.relu5 = nn.LeakyReLU(0.1)
self.conv6 = nn.Conv2d(32, 32, (4, 1))
nn.init.xavier_uniform_(self.conv6.weight)
self.relu6 = nn.LeakyReLU(0.1)
self.conv7 = nn.Conv2d(32, 32, (1, 10), stride=(1, 2))
nn.init.xavier_uniform_(self.conv7.weight)
self.relu7 = nn.LeakyReLU(0.1)
self.conv8 = nn.Conv2d(32, 32, (4, 1))
nn.init.xavier_uniform_(self.conv8.weight)
self.relu8 = nn.LeakyReLU(0.1)
self.conv9 = nn.Conv2d(32, 32, (4, 1))
nn.init.xavier_uniform_(self.conv9.weight)
self.relu9 = nn.LeakyReLU(0.1)
# Build the inception module
# convsecond_1 = Conv2D(64, (1, 1), padding="same")(conv_first1)
self.conv10 = nn.Conv2d(32, 64, (1, 1))
nn.init.xavier_uniform_(self.conv10.weight)
self.relu10 = nn.LeakyReLU(0.1)
self.conv11 = nn.Conv2d(64, 64, (3, 1), padding=(1, 0))
nn.init.xavier_uniform_(self.conv11.weight)
self.relu11 = nn.LeakyReLU(0.1)
self.conv12 = nn.Conv2d(32, 64, (1, 1))
nn.init.xavier_uniform_(self.conv12.weight)
self.relu12 = nn.LeakyReLU(0.1)
self.conv13 = nn.Conv2d(64, 64, (5, 1), padding=(2, 0))
nn.init.xavier_uniform_(self.conv13.weight)
self.relu13 = nn.LeakyReLU(0.1)
self.maxpool1 = nn.MaxPool2d((3, 1), stride=(1, 1), padding=(1, 0))
self.conv14 = nn.Conv2d(32, 64, (1, 1))
nn.init.xavier_uniform_(self.conv14.weight)
self.rnn1 = nn.LSTM(100, 64)
self.linear1 = nn.Linear(64, 3)
self.softmax1 = nn.Softmax(dim=1)
## testing layers
self.linear1 = nn.Linear(3200, 3)
def forward(self, x):
### build the convolutional block ###
x = self.conv1(x)
x = self.relu1(x)
x = F.pad(x, (0, 0, 1, 2)) # [left, right, top, bot]
# x = F.pad(x, (0, 0, 1, 2)) # [left, right, top, bot]
### SHOULD I USE 1,2 or 2,1 padding?
x = self.conv2(x)
x = self.relu2(x)
x = F.pad(x, (0, 0, 1, 2)) # [left, right, top, bot]
x = self.conv3(x)
x = self.relu3(x)
x = self.conv4(x)
x = self.relu4(x)
x = F.pad(x, (0, 0, 1, 2)) # [left, right, top, bot]
x = self.conv5(x)
x = self.relu5(x)
x = F.pad(x, (0, 0, 1, 2)) # [left, right, top, bot]
x = self.conv6(x)
x = self.relu6(x)
x = self.conv7(x)
x = self.relu7(x)
x = F.pad(x, (0, 0, 1, 2)) # [left, right, top, bot]
x = self.conv8(x)
x = self.relu8(x)
x = F.pad(x, (0, 0, 1, 2)) # [left, right, top, bot]
x = self.conv9(x)
x = self.relu9(x)
## testing layers
x = x.view(x.shape[0], x.shape[1] * x.shape[2] * x.shape[3])
x = self.linear1(x)
x = self.softmax1(x)
return x
The bigger the learning rate the shorter the flat part and the steeper the curve once it gets going which makes sense.
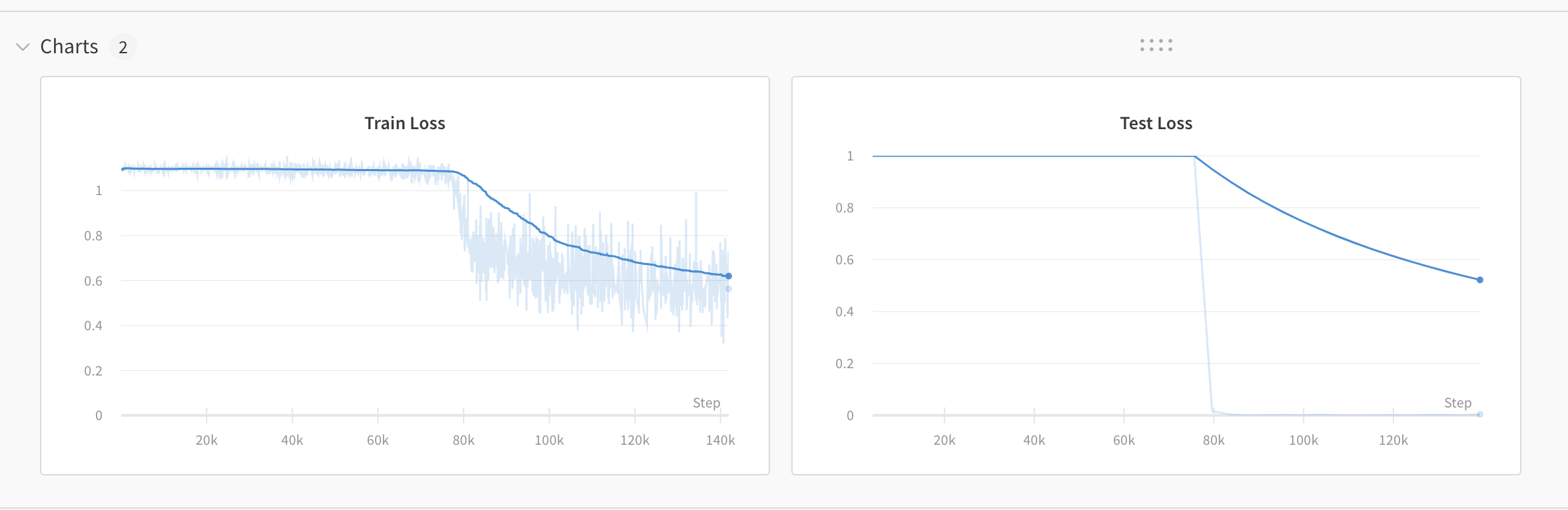
It seems like the weights and biases of the convolutional layers are small on the flat part
