Hi, I’m trying to fine-tune BERT for entity recognition task.
While training, the train loss decreases steadily and evaluation scores increase as I expected, but suddenly at a certain point, the train loss becomes large and all evaluation scores become 0.
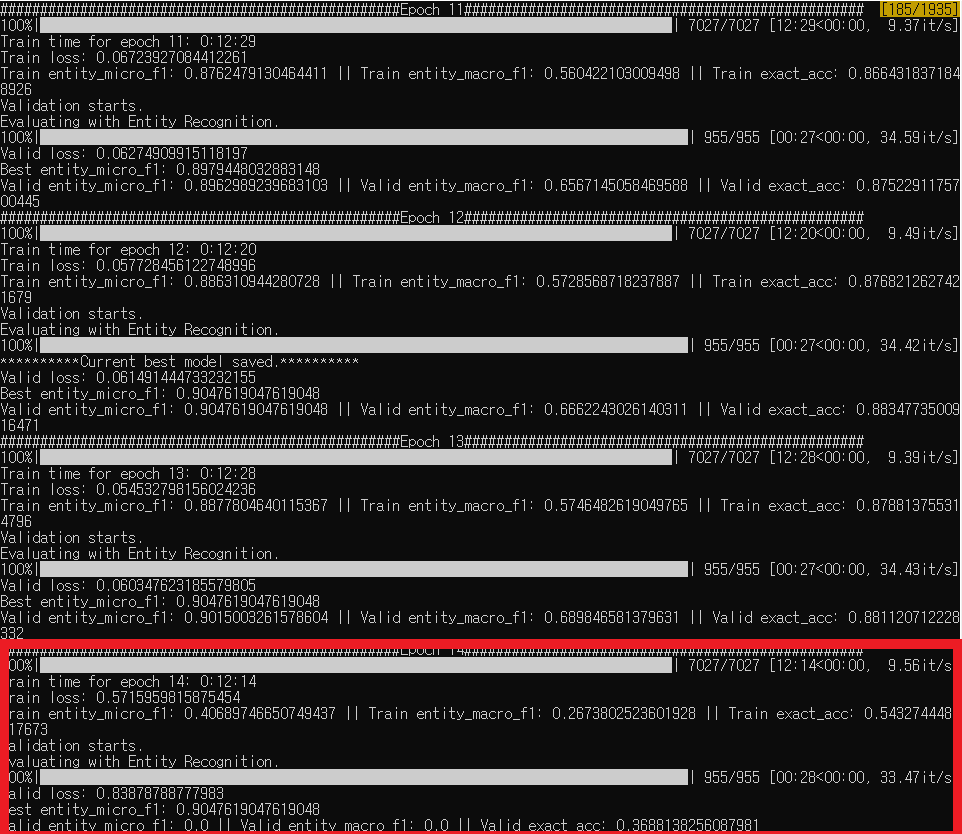
I think this might be vanishing/exploding gradient, but I don’t know how to fix this.
I added gradient clipping and learning rate scheduling which reduce the learning rate if the validation score does not decrease.
And I also initialized the weights of output layer for token-level classification into the xavier-uniform.
Here are specific details for my training.
- encoder: bert-base-uncased
- initialization of output layer: xavier uniform
- batch size: 8
- starting learning rate: 5e-5
- scheduler: ReduceLROnPlateau
- factor: 0.1
- patience: 3 epochs
- threshold: 1e-3
- optimizer: AdamW
- loss: CrossEntropy
- gradient clipping: 1.0
Thank you.