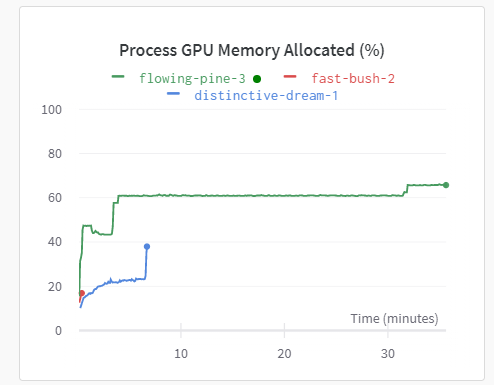
Hi!
So I have a question, I have this recursive algorithm to train multiple Neural Networks in different domains, but same architecture , every time you go deeper into the algorithm the less training data you have, meaning it should be faster training the deeper you go.
I tested my algorithm with a small(2000) training set to be sure that it worked. And it does work! But now i want to try it with more real world training set, with size 262144(512x512). Since I knew I was going to work with the GPU so I tried to carefully move variables to the GPU only if I needed it.
When I ran it, I saw that the first network I trained(with the biggest training set of 512x512 samples) trains quite fast it takes 130s. However, next one that is going to be trained using only 60% of the data to train it, takes significantly way more(I have taken the time to see how much it actually takes because it so long). But if I test the network using that 60% of the data to train it, it takes approximately 50s.
Now that you have the context my question is the following. Is there any way that the first network I trained slows the second one?
I will show you the NN and the my training functions:
class MLPflat(nn.Module):
def __init__(self,in_dim: int, out_dim: int, N, H):
super().__init__()
assert(N > 0)
assert(H > 0)
net = [nn.Linear(in_dim, H),nn.BatchNorm1d(H), nn.LeakyReLU()]
for _ in range(N-1): # make N layers
net += [nn.Linear(H, H),nn.BatchNorm1d(H), nn.LeakyReLU()]
net += [nn.Linear(H,out_dim,bias=False)]
self.model = nn.Sequential(*net)
def forward(self, x):
x = self.model(x)
output = x
return output
I use N(hidden layers) = 5 and H = 64.
def train(phi,train_loader,epochs,criterion,optimizer):
fit_start_time = time.time()
for epoch in range(epochs):
batch = 0
for x_batch, y_batch in train_loader:
optimizer.zero_grad()
print(x_batch.shape)
y_pred = phi(x_batch.to(device))
loss = criterion(y_pred.squeeze(), y_batch.to(device).squeeze())
loss.backward(retain_graph=True)# I retain the graph because I get an error if I don't do it.
optimizer.step()
batch+=1
fit_end_time = time.time()
print("Total time = %f" % (fit_end_time - fit_start_time))
I tried to do is to get rid any tensor inside of the GPU I don’t need. However it didn’t seem to improve.
I think that this problem is not really apparent in with really small training sets, but only comes when I train it with big amounts of training samples.
I would love to hear if this problem sounds like anything you have encounter before. If this is not enough let me know and I could elaborate more on my algorithm.