Hi,
I recently bought RTX 3060 Ti GPU before that I used to work on the google collab free version (Tesla T4 GPU). I am working on a Computer vision project so I was working with YOLO v5 on collab so now I want to shift over to my local pc. I downloaded yolov5 on my local machine and made an environment variable for it and downloaded the required dependency libraries.
How I downloaded the PyTorch and Cuda:
- Made an Environment variable using VS Community
- Installed Pip
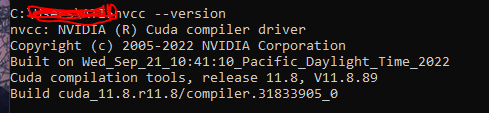
- Then used the Pytorch site to download CUDA (cuda 11.7) I used below command:
“pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117”
Afterward, I verified if the GPU is working using below commands:
import torch
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))
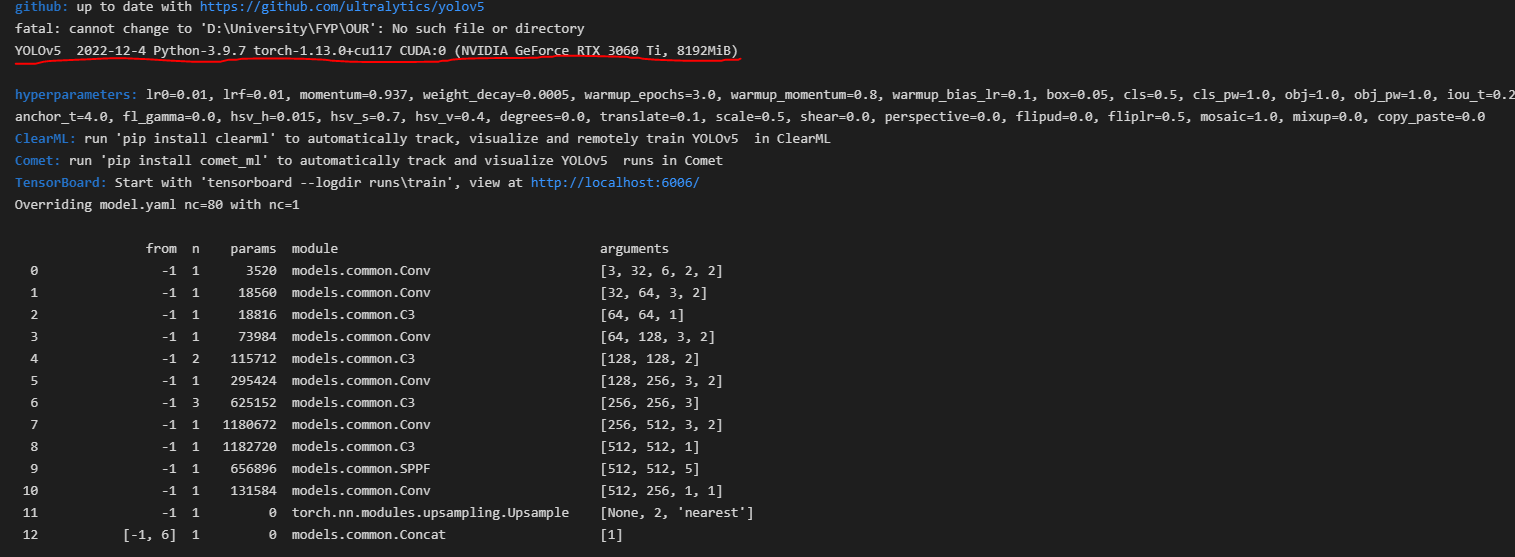
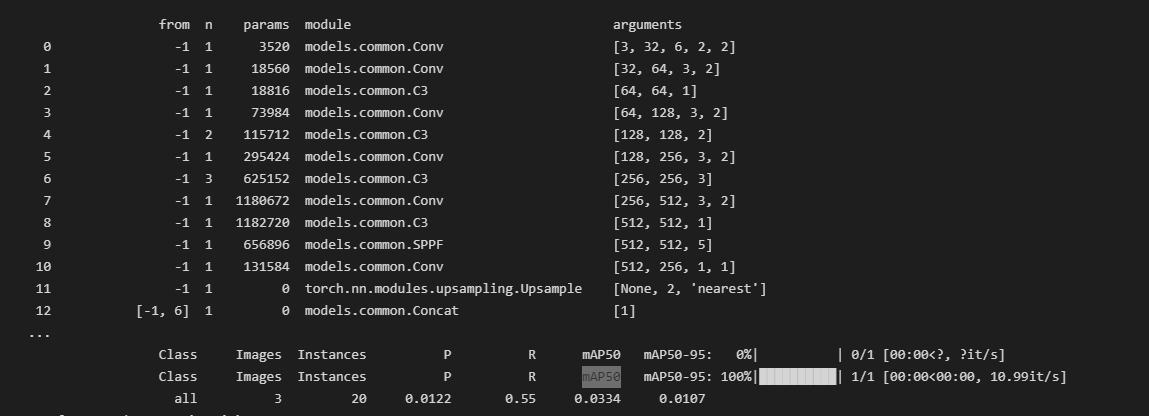
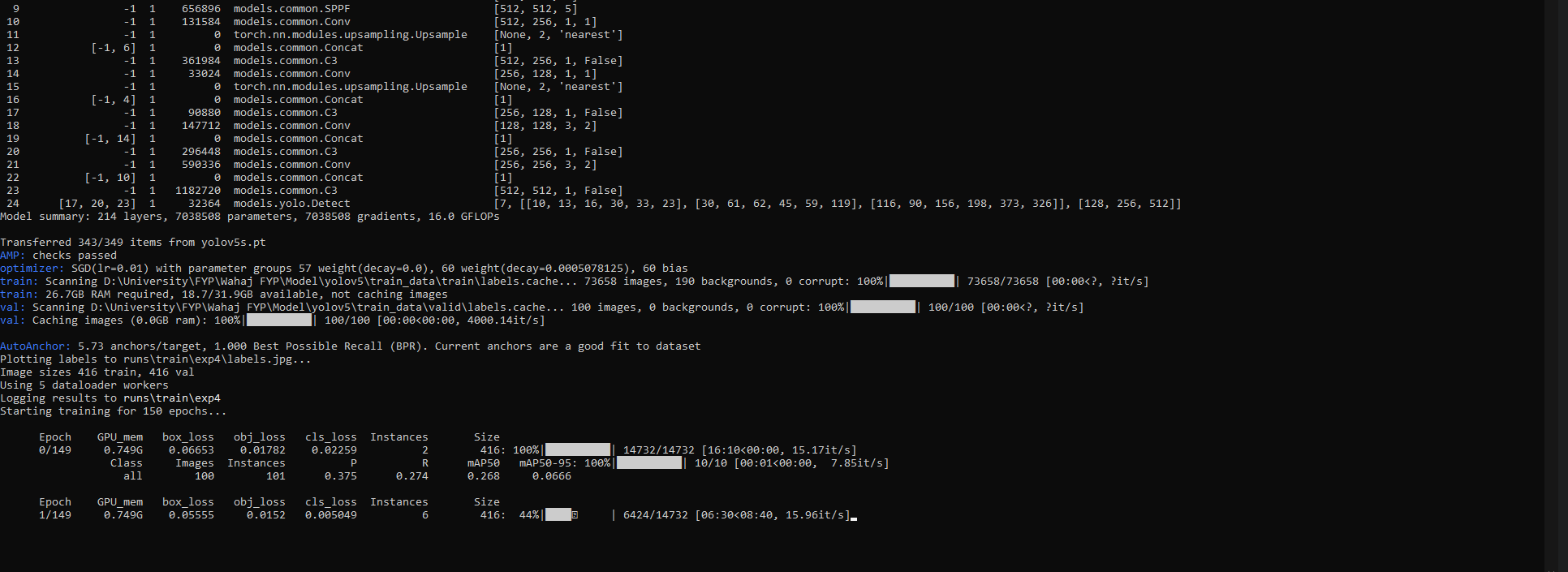
and it displayed the GPU there. Then I ran training for 3 epochs to test my gpu with same dataset which I used on collab that took only around 30 seconds to complete (Tesla T4 which has around 2000 Cuda cores less than RTX 3060 Ti)on the other hand my GPU kept running for around 3 hours but didn’t stop (So I Interrupted it)
NOTE: I didn’t download or used cudnn (as I followed a youtube tutorial and the guy didn’t download that). Secondly, When I start training my C Drive got filled up (I don’t know why) so I uninstalled python from C and downloaded it to D (but that again didn’t help). Thirdly my GPU utilization is avg 15 to 20 while training
Please help me in this matter I shall be really thankful to you guys as I have my University FYP due and this is making issues in doing my work smoothly.