Link to my notebook. Hey guys I am trying to predict car model using Stanford Car Dataset. However, as they did not have labels on their dataset, I have connected the image with label. And I tried to replicate Image loader by creating another custom Dataloader. However, my training is not working. Can you guys please check it out??
What exactly is not working?
Are you getting any errors using your new dataset or is the model accuracy bad?
In the latter case, I would recommend to try to overfit a small data sample (e.g. just 10 samples) and make sure your model is able to do so by playing around with the hyper-parameters.
Hi @ptrblck. Here I want to predict the car label using the training data. Therefore, I am using one-hot encoding to represent the total of 196 classes. However, when I am training, then the F score and other losses shows some weird numbers. Ex) F score not going up at all or even decrease when training loss and valid loss is decreasing. Can you take a look at it and what is going wrong?
It seems you are using F.cross_entropy as your loss function, which will not accept one-hot encoded target. Instead the target should contain the class indices and have the shape [batch_size] for a multi-class classification.
Did you also check the loss curves and the accuracy? Is the accuracy going up?
I should check the accuracy. However. what do you mean by target should contain the class indices and have the shape [batch_size]? Sorry, but I am beginner. To my understanding, the class indices sounds like it should have integer value which matches up with the class name. Could you please clarify for me?
the accuracy is also not increasing @ptrblck. Can you please take a look at it if you don’t mind? Thanks for your help.
As described in the docs for nn.CrossEntropyLoss, the target should use class indices and be a LongTensor.
Here is a small example for 5 classes:
batch_size = 10
nb_classes = 5
output = torch.randn(batch_size, nb_classes, requires_grad=True) # your model output
target = torch.randint(0, nb_classes, (batch_size,))
print(target)
> tensor([1, 4, 2, 2, 2, 0, 2, 1, 3, 3])
criterion = nn.CrossEntropyLoss()
loss = criterion(output, target)
If you are passing one-hot encoded targets, the criterion should raise an error, since your target tensor should have two dimensions in the one-hot version.
Could you check your current target and make sure it contains the expected values in the expected shape?
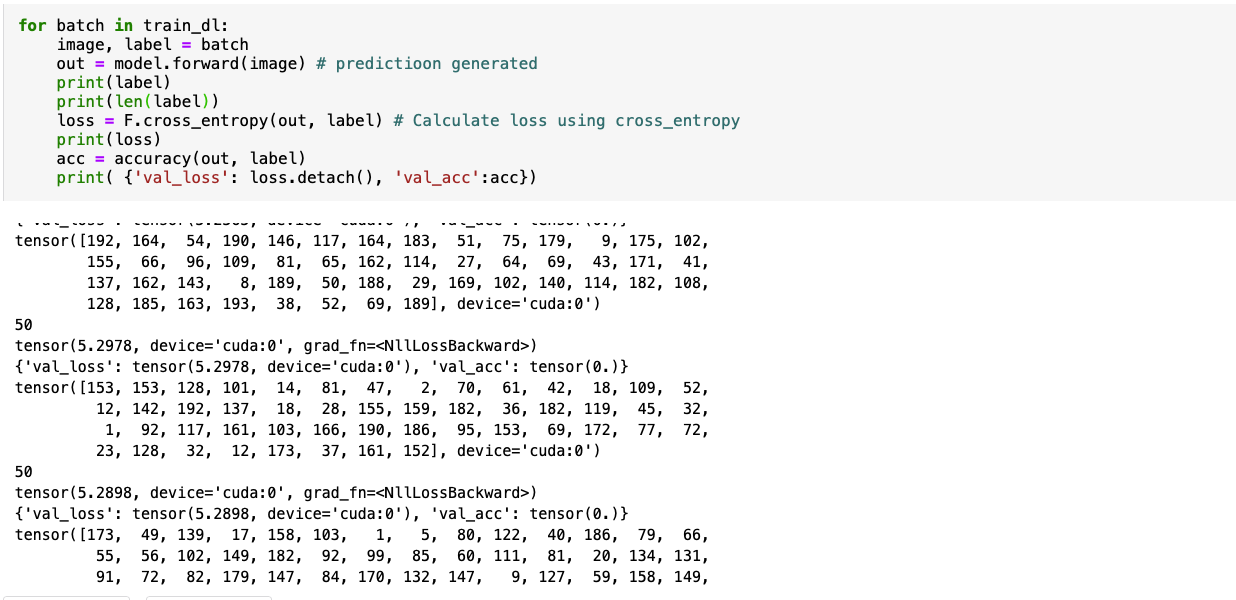
If you see the picture, it is visible that both validation and training set loss Is working. I have changed the structure of the code also. Now I separated the test and train image first, then I loaded using custom datasset. Batch size is 50, so I don’t know what is going on. Thank you for your help.
@ptrblck, hey it seems like I have used cross entropy and sigmoid, which lead to the breakdown. I totally forgot that sigmoid was used only for 2 cases and softmax for multi class classification.
Note that F.cross_entropy does not need a softmax, but expects the raw logits. You should therefore not use any activation function after your last linear layer. (Unsure, if you are going to swap the sigmoid for a softmax)