Hello everyone,
I try to train a MaskRCNN ResNet50 model with ~5000 images, using torchvision (based on this tutorial [TorchVision Object Detection Finetuning Tutorial — PyTorch Tutorials 2.2.0+cu121 documentation]). After one day with no return, I get this:
Epoch: [0] [ 0/1643] eta: 1:02:35 lr: 0.000010 loss: 3.7346 (3.7346) loss_classifier: 1.6762 (1.6762) loss_box_reg: 0.1342 (0.1342) loss_mask: 1.7567 (1.7567) loss_objectness: 0.1513 (0.1513) loss_rpn_box_reg: 0.0163 (0.0163) time: 2.2856 data: 0.1504 max mem: 6379
Epoch: [0] [ 200/1643] eta: 0:52:33 lr: 0.001009 loss: 0.8649 (1.2449) loss_classifier: 0.1609 (0.2664) loss_box_reg: 0.1137 (0.1101) loss_mask: 0.5193 (0.7439) loss_objectness: 0.0410 (0.1019) loss_rpn_box_reg: 0.0137 (0.0225) time: 2.3259 data: 0.0890 max mem: 10659
Epoch: [0] [ 400/1643] eta: 0:47:08 lr: 0.002008 loss: 0.8563 (1.0653) loss_classifier: 0.1598 (0.2176) loss_box_reg: 0.1226 (0.1216) loss_mask: 0.5100 (0.6313) loss_objectness: 0.0387 (0.0746) loss_rpn_box_reg: 0.0077 (0.0201) time: 2.5439 data: 0.0874 max mem: 10659
Epoch: [0] [ 600/1643] eta: 1 day, 4:12:41 lr: 0.003007 loss: 0.7584 (0.9834) loss_classifier: 0.1494 (0.1987) loss_box_reg: 0.1150 (0.1239) loss_mask: 0.4441 (0.5806) loss_objectness: 0.0200 (0.0611) loss_rpn_box_reg: 0.0075 (0.0191) time: 443.5763 data: 0.1023 max mem: 10659
And then nothing happens (I tried waiting for several days), there is no error and no more training steps calculated.
When I type nvidia-smi:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.156.00 Driver Version: 450.156.00 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GRID T4-16C On | 00000000:02:01.0 Off | 0 |
| N/A N/A P0 N/A / N/A | 16274MiB / 16384MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 2324 C ...v/envs/default/bin/python 14054MiB |
+-----------------------------------------------------------------------------+
I tried reducing batch size or number of images but I get the same problem each time.
I use torch 1.10.1 and torchvision 0.11.2 and I get this from torch:
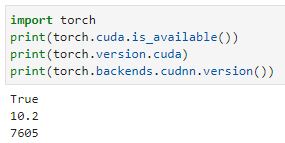
Any idea what causes the problem ?
Thanks