class MyCustomDataset():
def __init__(self, cropped_1x32_dataset, targets, transforms=None):
for i in range(32):
self.__setattr__('data_{}'.format(i), cropped_1x32_dataset[i])
self.targets = targets
self.transforms = transforms
def __getitem__(self, index):
for i in range(32):
globals()['data_{}'.format(i)] = self.__getattribute__('data_{}'.format(i))[index]
y = self.targets[index]
data = [globals()['data_{}'.format(i)] for i in range(32)]
if self.transforms is not None:
for i in range(32):
data[i] = self.transforms(ToPIL(data[i]))
return data,y
def __len__(self):
return len(self.data_0)
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.4914, 0.4824, 0.4467),
std=(0.2471, 0.2436, 0.2616)),
])
# train
my_train_dataset = MyCustomDataset(train_cropped_1x32_dataset, train_dataset.targets, transform_train)
my_train_loader = torch.utils.data.DataLoader(dataset = my_train_dataset,
batch_size = batch_size,
shuffle = True,
num_workers=os.cpu_count())
os.environ["CUDA_VISIBLE_DEVICES"] = '1'
batch_size = 128
learning_rate = 0.1
device = 'cuda'
model = Vgg16()
model.to(device)
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss()
if torch.cuda.device_count() > 0:
print("USE", torch.cuda.device_count(), "GPUs!")
model = nn.DataParallel(model)
cudnn.benchmark = True
else:
print("USE ONLY CPU!")
if torch.cuda.is_available():
model.cuda()
def train(epoch):
model.train()
train_loss = 0
total = 0
correct = 0
for batch_idx, (cropped_1x32_dataset, target) in enumerate(my_train_loader):
for i in range(32):
cropped_1x32_dataset[i] = cropped_1x32_dataset[i].to(device)
target = target.to(device)
optimizer.zero_grad()
output = model(cropped_1x32_dataset, return_features=False)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.data
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += predicted.eq(target.data).cpu().sum()
if batch_idx % 10 == 9:
print('Epoch: {} | Batch: {} | Loss: ({:.4f}) | Acc: ({:.2f}%) ({}/{})'
.format(epoch+1, batch_idx+1, train_loss/(batch_idx+1), 100.*correct.item()/total, correct, total))
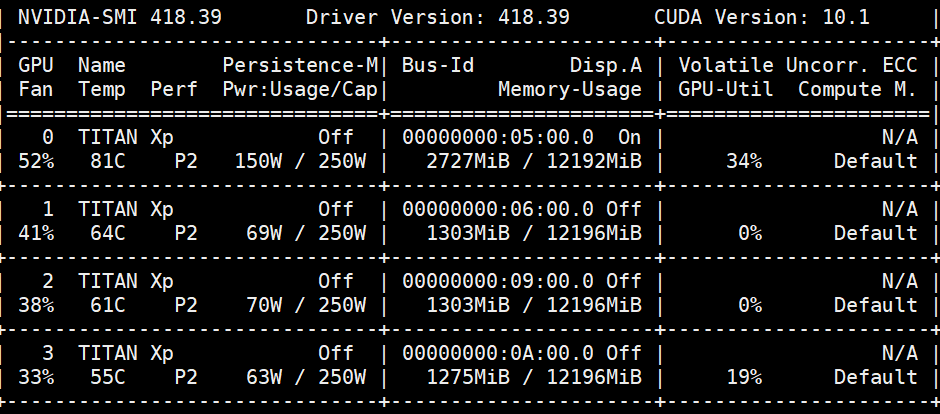
I’m working on os.environ["CUDA_VISIBLE_DEVICES"] = '1'
But as you can see, when I check nvidia-smi almost everytime volatile shows 0%.
Sometimes I shows upto 10~30%. So training speed is so slow.
How can I use full GPU power to speed up train?
Thank you.