Hello,
I am training a custom Encoder-Decoder network but the training gets stuck at Epoch 3. Nothing happens for about 2 hours. I will share the Dataset class and the DataLoader object. The version if CUDA and GPU can be seen in the pic below.
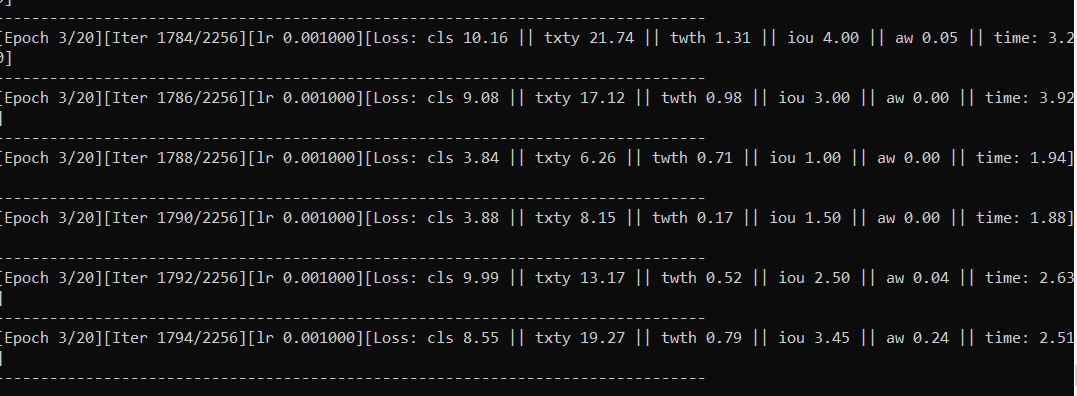
Training stuck here:
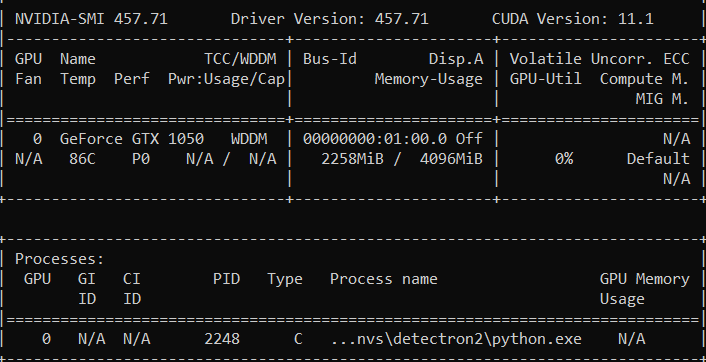
nvidia-smi output looks like this:
The __getitem__ method of the dataset class looks like this:
def __init__(self,
images_dir,
annots_dir,
train=True,
img_size=(512, 1536),
stride=4,
model='custom',
transforms=None):
"""
:param root: dataset directory
:param filenames: filenames inside the root directory
:param labels: Object Detection Labels
"""
super(CustomDataset).__init__()
self.images_dir = images_dir
self.annots_dir = annots_dir
self.train = train
self.image_size = img_size
self.stride = stride
self.transforms = transforms
self.model = model
# Load the image and annotation files from the dataset
# self.image_files, self.annot_files = self._load_image_and_annot_files()
self.image_files = [os.path.join(self.images_dir, idx) for idx in os.listdir(self.images_dir)]
self.annot_files = [os.path.join(self.annots_dir, idx) for idx in os.listdir(self.annots_dir)]
def __getitem__(self, index):
"""
:param index: index...0 to N
:return: tensor_image and tensor_label
"""
# Image filename from _load_image_files()
# Load Image with _read_matrix() and label
curr_image_filename = self.image_files[index]
curr_annot_filename = self.annot_files[index]
# curr_image_filename = self.image_files[index]
# curr_annot_filename = self.annot_files[index]
np_image = self._read_matrix(raw_img=curr_image_filename)
np_image_normalized = np.squeeze(self._normalize_raw_img(np_image))
# label = self.labels[index]
boxes, classes, depths, tgts = self._load_annotations(curr_annot_filename)
# Normalize bounding boxes: range [0, 1]
targets_normalized = self._normalize_bbox(np_image_normalized, tgts)
# image and the corresponding label should be a tensor
torch_image = torch.from_numpy(np_image).reshape(1, 512, 1536).float() # dtype: torch.float64
torch_boxes = torch.from_numpy(boxes).type(torch.FloatTensor)
torch_depths = torch.from_numpy(depths)
if self.model == 'fasterrcnn':
# For FasterRCNN: As COCO format
area = (torch_boxes[:, 3] - torch_boxes[:, 1]) * (torch_boxes[:, 2] - torch_boxes[:, 0])
iscrowd = torch.zeros((boxes.shape[0],), dtype=torch.int64)
image_id = torch.Tensor([index])
torch_classes = torch.from_numpy(classes)
target = {'boxes': torch_boxes, 'labels': torch_classes.long(),
'area': area, 'iscrowd': iscrowd, 'image_id': image_id}
return torch_image, target
elif self.model == 'custom':
if self.train:
if self.transforms:
try:
tr = self.transforms()
transform_image, transform_boxes, labels = tr.__call__(np_image, tgts, tgts[:, :4], tgts[:, 4:])
transform_targets = np.hstack((np.array(transform_boxes), labels))
gt_tensor = gt_creator(img_size=self.image_size,
stride=self.stride,
num_classes=8,
label_lists=transform_targets)
return torch.from_numpy(transform_image).float(), gt_tensor
except IndexError:
pass
else:
gt_tensor = gt_creator(img_size=self.image_size,
stride=self.stride,
num_classes=8,
label_lists=targets_normalized)
return torch_image, gt_tensor
else:
return torch_image, targets_normalized
And in the train.py script the DataLoader object is:
train_loader = torch.utils.data.DataLoader(dataset=dataset,
shuffle=True,
batch_size=batch_size,
num_workers=0,
collate_fn=detection_collate,
pin_memory=True)
Why does the training get stuck? Is there an issue in the __getitem__ method? Or the DataLoader?
Thank You.