Hi,
I am training an actor-critic algorithm using my own code and I noticed the training time keeps increasing at every epoch.
I thought it could be a problem of continuously increasing the Computational Graph, but I think I am not doing anything wrong and when keeping track of the actor_loss and critic_loss backward times it doesn’t seem to be the issue, since their respective training times don’t increase drastically.
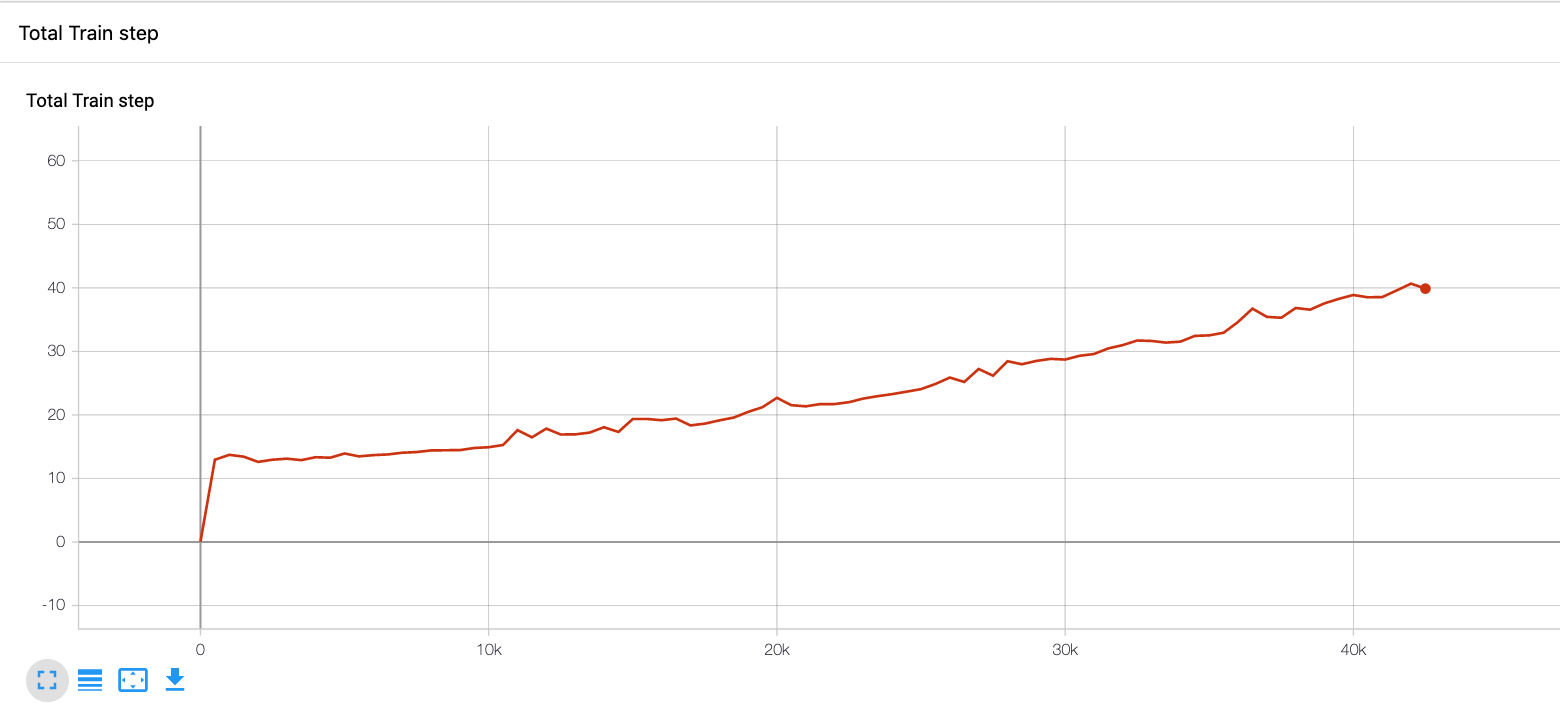
This is my training function, and the graph shown below, shows time of training every 500 training epochs (1 epoch goes once through the function ‘train’ below).
Any hints?
Thanks a lot in advance!
def train(self, episode_num=None):
self.memory.shuffle()
for num_batch, obs in enumerate(self.data_loader):
state, action, reward, next_state, done = obs[0]
state = state.to(torch.float32, copy=False)
action = action.to(torch.float32, copy=False)
reward = reward.to(torch.float32, copy=False)
next_state = next_state.to(torch.float32, copy=False)
done = done.to(torch.float32, copy=False)
current_Z, target_Z, tau_k = self.td(
state, action, reward, next_state, done)
self.critic_loss = self.criterion_critic(target_Z, current_Z, tau_k)
self.optimizer_critic.zero_grad()
self.critic_loss.backward()
self.optimizer_critic.step()
if self.num_train_steps % self.policy_update_freq == 0:
# Update policy network:
actor_loss_ = self.compute_actor_loss(state)
self.actor_loss = self.to_min*actor_loss_
self.optimizer_actor.zero_grad()
self.actor_loss.backward()
self.optimizer_actor.step()
# call @parameters.setter in NNQFunction
self.target_Q_function.parameters = \
self.Q_function.parameters
# call @parameters.setter in NNPolicyFunction
self.target_policy_function.parameters = \
self.policy_function.parameters