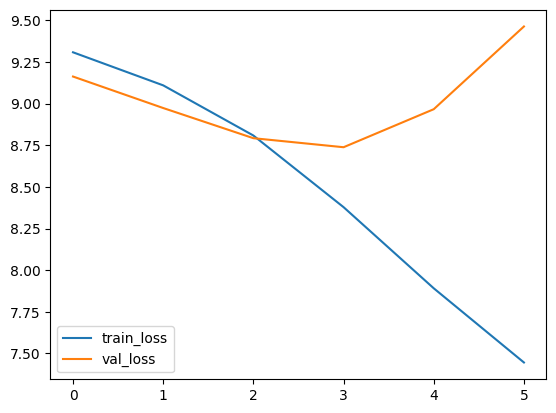
I am training a transformer model for english to hindi translation task. Train datasets contains 30k samples. And val dataset contains 5k samples. I tried regularising by adding dropout and weght_decay but model is still overfitting. What could be the possible solution to train model succesfully?
SRC_VOCAB_SIZE = len(vocab_transform[SRC_LANGUAGE])
TGT_VOCAB_SIZE = len(vocab_transform[TGT_LANGUAGE])
EMB_SIZE = 512
NHEAD = 8
FFN_HID_DIM = 512
BATCH_SIZE = 128
NUM_ENCODER_LAYERS = 3
NUM_DECODER_LAYERS = 3
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS, EMB_SIZE,
NHEAD, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE, FFN_HID_DIM, dropout=0.6)
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
transformer = transformer.to(DEVICE)
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = torch.optim.RAdam(transformer.parameters(), lr=1e-5, betas=(0.9, 0.98), eps=1e-9, weight_decay=1e-1)