Hello every one!
Sorry for redundancy, but I browsed all of the topics and none of them helped me.
I’m trying to reproduce this tutorial from Keras, which is indeed simple one, however I’m getting completely different result.
I used exactly the same preprocessing procedures for the dataset.
This is my snippet code:
class LSTM(torch.nn.Module):
def __init__(self, input_size, seq_length, hidden_state, output, batch_size=1, num_layers=1):
super(LSTM, self).__init__()
self.input_size = input_size
self.seq_length = seq_length
self.hidden_state = hidden_state
self.output = output
self.num_layers = num_layers
self.batch_size = batch_size
self.lstm = torch.nn.LSTM(input_size, hidden_state)
self.fc = torch.nn.Linear(hidden_state, output)
def forward(self, x):
h0 = Variable(torch.zeros(self.num_layers * 1, self.batch_size, self.hidden_state), requires_grad=True)
c0 = Variable(torch.zeros(self.num_layers * 1, self.batch_size, self.hidden_state), requires_grad=True)
out, _ = self.lstm(x, (h0, c0))
fc = self.fc(out)
return fc
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters())
for e in range(ep):
for i in range(len(trainX)):
input_ = torch.tensor(trainX[i]).reshape(1, 1, 1)
targ_ = torch.tensor(trainY[i])
out_ = model(input_)
loss = loss_fn(out_, targ_)
loss.backward()
optimizer.step()
Epoch [1/100], Loss: 0.0667
Epoch [2/100], Loss: 0.0045
Epoch [3/100], Loss: 0.0129
Epoch [4/100], Loss: 0.0090
Epoch [5/100], Loss: 0.0610
Epoch [6/100], Loss: 0.0400
Epoch [7/100], Loss: 0.0057
Epoch [8/100], Loss: 0.0008
Epoch [9/100], Loss: 0.0029
Epoch [10/100], Loss: 0.0004
Epoch [11/100], Loss: 0.0226
Epoch [12/100], Loss: 0.0634
Epoch [13/100], Loss: 0.0707
Epoch [14/100], Loss: 0.0308
Epoch [15/100], Loss: 0.0017
Epoch [16/100], Loss: 0.0027
Epoch [17/100], Loss: 0.0024
Epoch [18/100], Loss: 0.0034
Epoch [19/100], Loss: 0.0391
Epoch [20/100], Loss: 0.0837
Epoch [21/100], Loss: 0.0784
Epoch [22/100], Loss: 0.0276
Epoch [23/100], Loss: 0.0004
Epoch [24/100], Loss: 0.0062
Epoch [25/100], Loss: 0.0063
Epoch [26/100], Loss: 0.0008
Epoch [27/100], Loss: 0.0314
Epoch [28/100], Loss: 0.0842
Epoch [29/100], Loss: 0.0973
Epoch [30/100], Loss: 0.0488
Epoch [31/100], Loss: 0.0046
Epoch [32/100], Loss: 0.0043
Epoch [33/100], Loss: 0.0159
Epoch [34/100], Loss: 0.0064
Epoch [35/100], Loss: 0.0028
Epoch [36/100], Loss: 0.0299
Epoch [37/100], Loss: 0.0221
Epoch [38/100], Loss: 0.0029
Epoch [39/100], Loss: 0.0013
Epoch [40/100], Loss: 0.0047
Epoch [41/100], Loss: 0.0003
Epoch [42/100], Loss: 0.0102
Epoch [43/100], Loss: 0.0489
Epoch [44/100], Loss: 0.0829
Epoch [45/100], Loss: 0.0699
Epoch [46/100], Loss: 0.0243
Epoch [47/100], Loss: 0.0005
Epoch [48/100], Loss: 0.0049
Epoch [49/100], Loss: 0.0058
Epoch [50/100], Loss: 0.0002
Epoch [51/100], Loss: 0.0246
Epoch [52/100], Loss: 0.0763
Epoch [53/100], Loss: 0.1034
Epoch [54/100], Loss: 0.0702
Epoch [55/100], Loss: 0.0172
Epoch [56/100], Loss: 0.0001
Epoch [57/100], Loss: 0.0098
Epoch [58/100], Loss: 0.0092
Epoch [59/100], Loss: 0.0000
Epoch [60/100], Loss: 0.0233
Epoch [61/100], Loss: 0.0791
Epoch [62/100], Loss: 0.1174
Epoch [63/100], Loss: 0.0946
Epoch [64/100], Loss: 0.0345
Epoch [65/100], Loss: 0.0013
Epoch [66/100], Loss: 0.0068
Epoch [67/100], Loss: 0.0170
Epoch [68/100], Loss: 0.0070
Epoch [69/100], Loss: 0.0018
Epoch [70/100], Loss: 0.0368
Epoch [71/100], Loss: 0.0961
Epoch [72/100], Loss: 0.1305
Epoch [73/100], Loss: 0.1039
Epoch [74/100], Loss: 0.0414
Epoch [75/100], Loss: 0.0030
Epoch [76/100], Loss: 0.0052
Epoch [77/100], Loss: 0.0199
Epoch [78/100], Loss: 0.0164
Epoch [79/100], Loss: 0.0010
Epoch [80/100], Loss: 0.0127
Epoch [81/100], Loss: 0.0633
Epoch [82/100], Loss: 0.1211
Epoch [83/100], Loss: 0.1407
Epoch [84/100], Loss: 0.1012
Epoch [85/100], Loss: 0.0375
Epoch [86/100], Loss: 0.0023
Epoch [87/100], Loss: 0.0059
Epoch [88/100], Loss: 0.0226
Epoch [89/100], Loss: 0.0227
Epoch [90/100], Loss: 0.0051
Epoch [91/100], Loss: 0.0039
Epoch [92/100], Loss: 0.0421
Epoch [93/100], Loss: 0.1029
Epoch [94/100], Loss: 0.1469
Epoch [95/100], Loss: 0.1397
Epoch [96/100], Loss: 0.0832
Epoch [97/100], Loss: 0.0237
Epoch [98/100], Loss: 0.0002
Epoch [99/100], Loss: 0.0104
Epoch [100/100], Loss: 0.0274
The result which I should obtain is in that tutorial.
The first strange thing is that the loss is obviously does not converge, the second one is the graph.This is what I get after 100 epochs:
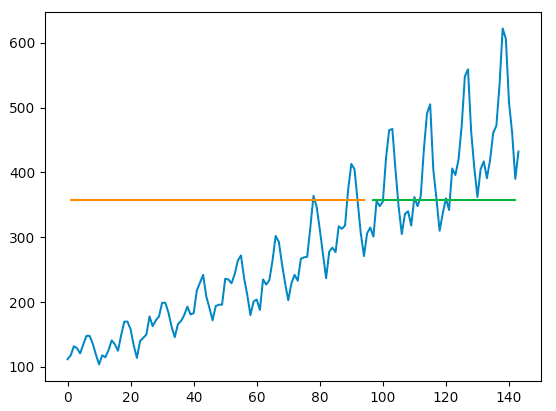
However, when I change optimizer to SGD and play around with lr, I start getting similar result, but still far away from the tutorial.
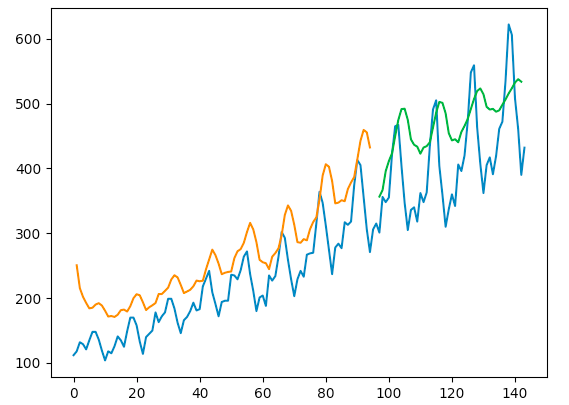
Things getting better when I use clipping (still not stable).
for name, p in model.named_parameters():
p.grad.data.clamp_(-5.0, 5.0)
p.data.add_(-1 * lr, p.grad.data)
The result:
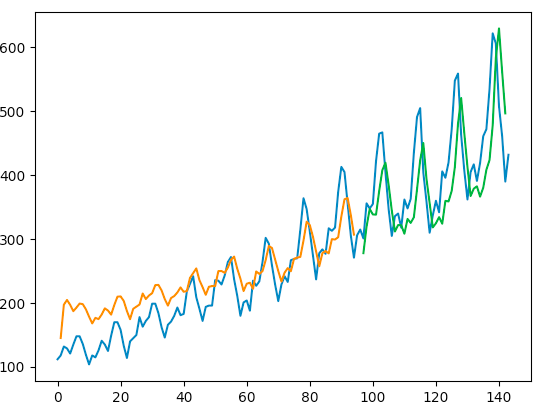
I would appreciate any help or advise.