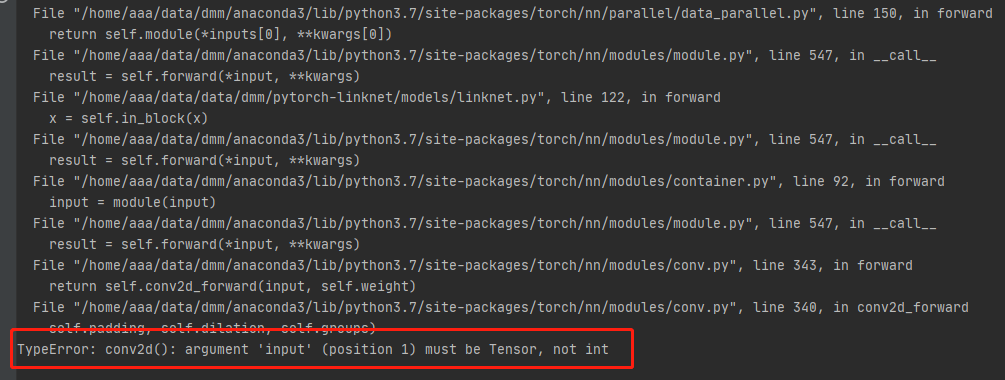
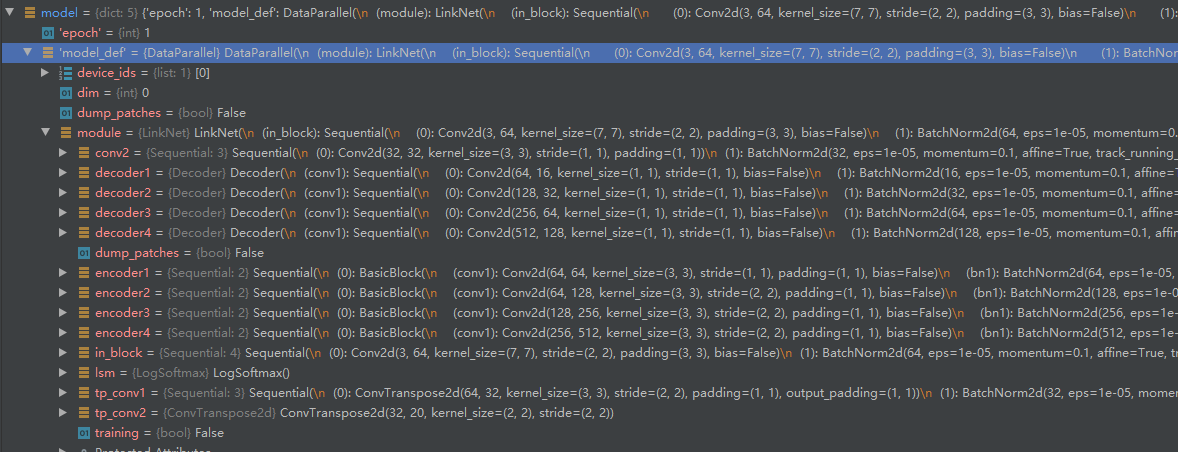
import os
import cv2
import time
import torch
import numpy as np
from argparse import ArgumentParser
import transforms
parser = ArgumentParser(description='e-Lab Segmentation Visualizer')
_ = parser.add_argument
_('--model_path', type=str, default='/media/', help='model to load')
_('--data_path', type=str, default='/media/', help='image folder')
_('--mode', type=int, default=0, help='mode 0, 1, 2')
_('--fullscreen', action='store_true', help='Show output in full screen')
args = parser.parse_args()
# Clear screen
print('\033[0;0f\033[0J')
# Color Palette
CP_R = '\033[31m'
CP_G = '\033[32m'
CP_B = '\033[34m'
CP_Y = '\033[33m'
CP_C = '\033[0m'
# Define color scheme
color_map = np.array([
[0, 0, 0], # Unlabled
[128, 64, 128], # Road
[244, 35, 232], # Sidewalk
[70, 70, 70], # Building
[102, 102, 156], # Wall
[190, 153, 153], # Fence
[153, 153, 153], # Pole
[250, 170, 30], # Traffic light
[220, 220, 0], # Traffic signal
[107, 142, 35], # Vegetation
[152, 251, 152], # Terrain
[70, 130, 180], # Sky
[220, 20, 60], # Person
[255, 0, 0], # Rider
[0, 0, 142], # Car
[0, 0, 70], # Truck
[0, 60, 100], # Bus
[0, 80, 100], # Train
[0, 0, 230], # Motorcycle
[119, 11, 32] # Bicycle
], dtype=np.uint8)
#device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Load model
model = torch.load('./media/model_best.pth')
model = torch.nn.DataParallel(model['model_def'](20))
model.load_state_dict(model['state_dict'])
model.cuda()
model.eval()
root_dir = os.path.join(args.data_path, 'stuttgart_0' + str(args.mode))
first_idx = [1, 3500, 5100]
last_idx = [599, 4599, 6299]
idx = first_idx[args.mode]
fps = 'NA'
pred_map = np.zeros((256, 512, 3), dtype=np.uint8)
pred_map = np.zeros((512, 1024, 3), dtype=np.uint8)
win_title = 'Overlayed Image'
if args.fullscreen:
cv2.namedWindow(win_title, cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty(win_title, cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
while idx <= last_idx[args.mode]:
# Load image, resize and convert into a 'batchified' cuda tensor
start_time = time.time()
filename = '{}/stuttgart_0{:d}_000000_{:06d}_leftImg8bit.png'.format(root_dir, args.mode, idx)
if os.path.isfile(filename):
x = cv2.imread(filename)
read_time = time.time() - start_time
resize = transforms.Resize(0.5)
x = resize(x)
prep_data = transforms.Compose([
#transforms.Crop((512, 512)),
transforms.ToTensor(),
transforms.Normalize([[0.485, 0.456, 0.406], [0.229, 0.224, 0.225]])
])
input_image = prep_data(x)
#input_image = torch.from_numpy(cv2.cvtColor(x, cv2.COLOR_BGR2RGB).transpose(2, 0, 1))/255
input_image = input_image.unsqueeze(0).float().cuda()
prep_time = time.time() - start_time - read_time
# Get neural network output
y = model(torch.autograd.Variable(input_image))
y = y.squeeze()
pred = y.data.gpu().numpy()
model_time = time.time() - start_time - read_time - prep_time
# Calculate prediction and colorized segemented output
prediction = np.argmax(pred, axis=0)
num_classes = 20
pred_map *= 0
for i in range(num_classes):
pred_map[prediction == i] = color_map[i]
pred_map_BGR = cv2.cvtColor(pred_map, cv2.COLOR_RGB2BGR)
overlay = cv2.addWeighted(x, 0.5, pred_map_BGR, 0.5, 0)
pred_time = time.time() - start_time - read_time - prep_time - model_time
#cv2.imshow('Original Image', x_rescaled)
#cv2.imshow('Segmented Output', pred_map_BGR)
cv2.imshow(win_title, overlay)
disp_time = time.time() - start_time - read_time - prep_time - model_time - pred_time
fps = 1/(time.time() - start_time)
print("{}Read: {}{:4.2f} ms | {}Norm:: {}{:4.2f} ms | {}Model: {}{:4.2f} ms | {}Predict: {}{:4.2f} ms | {}Display: {}{:4.2f} ms".format(
CP_Y, CP_C, read_time*1000, CP_G, CP_C, prep_time*1000, CP_G, CP_C, model_time*1000,
CP_R, CP_C, pred_time*1000, CP_B, CP_C, disp_time*1000))
else:
print("{}Warning{}!!! {}{} image unavailable{}.".format(CP_R, CP_C, filename, CP_R, CP_C))
idx += 1
if cv2.waitKey(1) == 27: # ESC to stop
break