I’ve forked the official word level language model of PyTorch. I was managed to train the network and arrived at the following result.
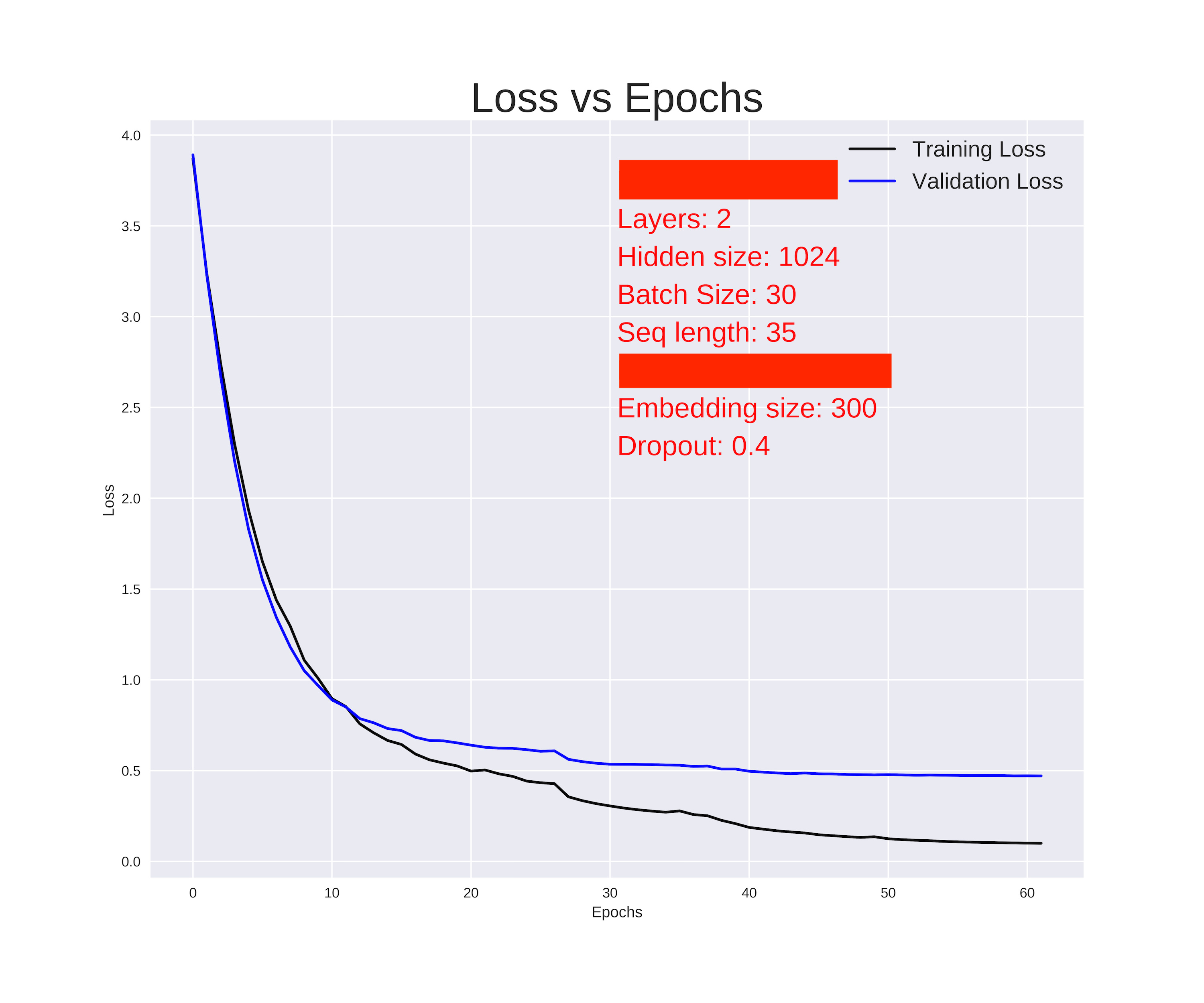
Have a look at the code.
def batchify(data, bsz):
# Work out how cleanly we can divide the dataset into bsz parts.
nbatch = data.size(0) // bsz
# Trim off any extra elements that wouldn't cleanly fit (remainders).
data = data.narrow(0, 0, nbatch * bsz)
# Evenly divide the data across the bsz batches.
data = data.view(bsz, -1).t().contiguous()
return data.to(device)
def get_batch(source, i):
seq_len = min(seq_length, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].view(-1)
return data, target
def repackage_hidden(h):
"""Wraps hidden states in new Tensors, to detach them from their history."""
if isinstance(h, torch.Tensor):
return h.detach()
else:
return tuple(repackage_hidden(v) for v in h)
class RNNModel(nn.Module):
"""Container module with an encoder, a recurrent module, and a decoder."""
def __init__(self, ntoken, ninp, nhid, nlayers, dropout=0.5, tie_weights=False):
super(RNNModel, self).__init__()
self.drop = nn.Dropout(dropout)
self.encoder = nn.Embedding(ntoken, ninp)
self.LSTM = nn.LSTM(ninp, nhid, nlayers, dropout=dropout)
self.decoder = nn.Linear(nhid, ntoken)
self.init_weights()
self.nhid = nhid
self.nlayers = nlayers
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, input, hidden):
emb = self.drop(self.encoder(input))
output, hidden = self.LSTM(emb, hidden)
output = self.drop(output)
decoded = self.decoder(output.view(output.size(0)*output.size(1), output.size(2)))
return decoded.view(output.size(0), output.size(1), decoded.size(1)), hidden
def init_hidden(self, bsz):
weight = next(self.parameters())
return (weight.new_zeros(self.nlayers, bsz, self.nhid),
weight.new_zeros(self.nlayers, bsz, self.nhid))
def evaluate(data_source, eval_batch_size):
# Turn on evaluation mode which disables dropout.
model.eval()
total_loss = 0.
ntokens = vocab_size
hidden = model.init_hidden(eval_batch_size)
with torch.no_grad():
for i in range(0, data_source.size(0) - 1, seq_length):
data, targets = get_batch(data_source, i)
output, hidden = model(data, hidden)
output_flat = output.view(-1, ntokens)
total_loss += len(data) * criterion(output_flat, targets).item()
hidden = repackage_hidden(hidden)
return total_loss / len(data_source)
def train():
# Turn on training mode which enables dropout.
model.train()
total_loss = 0.
start_time = time.time()
ntokens = vocab_size
hidden = model.init_hidden(batch_size)
for batch, i in enumerate(range(0, train_data.size(0) - 1, seq_length)):
data, targets = get_batch(train_data, i)
# Starting each batch, we detach the hidden state from how it was previously produced.
# If we didn't, the model would try backpropagating all the way to start of the dataset.
hidden = repackage_hidden(hidden)
model.zero_grad()
output, hidden = model(data, hidden)
loss = criterion(output.view(-1, ntokens), targets)
loss.backward()
# `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs.
clip_grad_norm_(model.parameters(), 0.25)
for p in model.parameters():
p.data.add_(-learning_rate, p.grad.data)
total_loss += loss.item()
if batch % log_interval == 0 and batch > 0:
cur_loss = total_loss / log_interval
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches | lr {:5.4f} | ms/batch {:5.2f} | '
'loss {:5.2f} | ppl {:8.2f} |'.format(
epoch, batch, len(train_data) // seq_length, learning_rate,
elapsed * 1000 /log_interval, cur_loss, math.exp(cur_loss)))
total_loss = 0
start_time = time.time()
best_val_loss = None
training_loss = []
validation_loss = []
# At any point you can hit Ctrl + C to break out of training early.
try:
for epoch in range(1, num_epochs+1):
epoch_start_time = time.time()
train()
val_loss = evaluate(val_data, eval_batch_size)
tr_loss = evaluate(train_data, batch_size)
training_loss.append(tr_loss)
validation_loss.append(val_loss)
print('-' * 122)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} | '
'valid ppl {:8.2f} | training loss {:5.2f} | training ppl {:8.2f} |'.format(epoch, (time.time() - epoch_start_time),
val_loss, math.exp(val_loss), tr_loss, math.exp(tr_loss)))
print('-' * 122)
# Save the model if the validation loss is the best we've seen so far.
if not best_val_loss or val_loss < best_val_loss:
torch.save(model.state_dict(), "model.pt")
best_val_loss = val_loss
else:
# Anneal the learning rate if no improvement has been seen in the validation dataset.
learning_rate = learning_rate /1.5
except KeyboardInterrupt:
print('-' * 122)
print('Exiting from training early')
When I tried to get the saved model to reproduce my results, I got the following result.
End of training | test loss 17.28 | test ppl 32104905.14
The code I used is,
model = RNNModel(ntoken=vocab_size, ninp=embed_size, nhid=hidden_size, nlayers=num_layers, dropout=dropout_value).to(device)
model.load_state_dict(torch.load("model.ckpt"))
criterion = nn.CrossEntropyLoss()
What is wrong here? I’m starting this thread as an extension of the discussion happened here directed by ptrblck