Hello everyone. In the audio classification task, the data is seriously unbalanced, and there is a similar long-tail phenomenon, resulting in very few samples that cannot be identified. how to solve this problem? thank you.
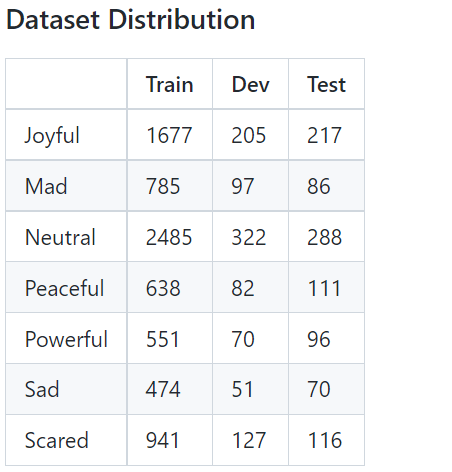
Hello everyone. In the audio classification task, the data is seriously unbalanced, and there is a similar long-tail phenomenon, resulting in very few samples that cannot be identified. how to solve this problem? thank you.