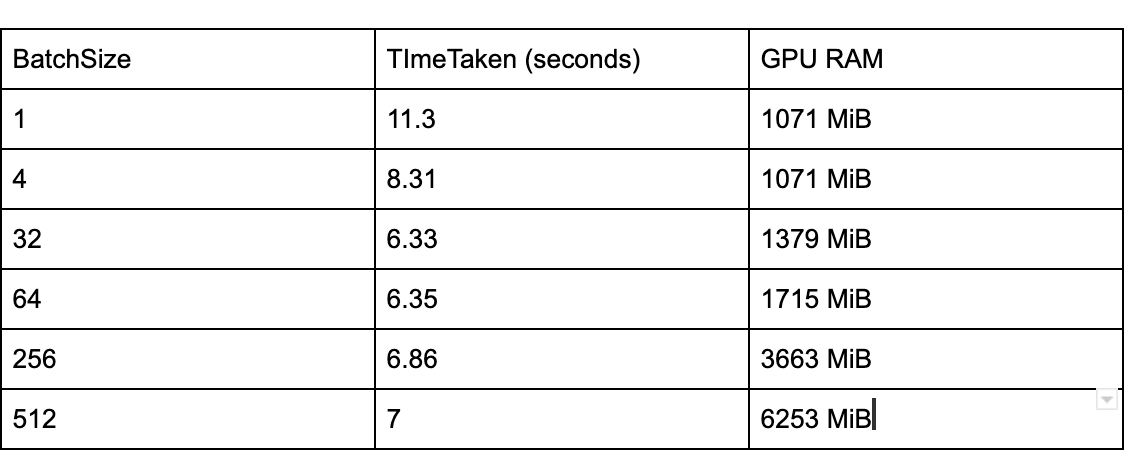
Im trying to see the effect of batchsize on time taken for inference on BERT model. I used different batchsizes to perform inference , I get inference speeding up until certain batchsizes and increasing slowly after a certain batchsize. I am attaching the GPU RAM and time taken for inference in the below table for different batch sizes
GPU used is GeForce GTX 1080
GPU utilisation from nvidia-smi command is always 100% . I understand this utilisation does not correspond to the GPU resource utilisation.Im wondering if all the GPU resources are utilised at batchsize 32 without consuming all the RAM. Is there a way to monitor the actual GPU resource utilization?
Adding the code that is profiled
start_time = time.time()
for batch_num,(input_ids, input_mask, segment_ids) in enumerate(tqdm(pred_dataloader, desc="Predicting")):
percent_done = float(batch_num)*100/num_batches
input_ids = input_ids.to(device)
input_mask = input_mask.to(device)
segment_ids = segment_ids.to(device)
with torch.no_grad():
logits, _ = model(input_ids, segment_ids, input_mask)
logit_max = torch.max(F.softmax(logits, dim=1), dim=1)
logits_soft = F.softmax(logits, dim=1).cpu().numpy()
all_preds = np.concatenate((all_preds, logits_soft))
logits = torch.argmax(F.log_softmax(logits, dim=1), dim=1)
logits = logits.detach().cpu().numpy()
logit_max = logit_max.values.detach().cpu().numpy()
pred_vals.extend(logit_max)
preds.extend(logits)
all_preds = all_preds[1:]
logger.info("TIme for batch loop %f" % (time.time() - start_time))