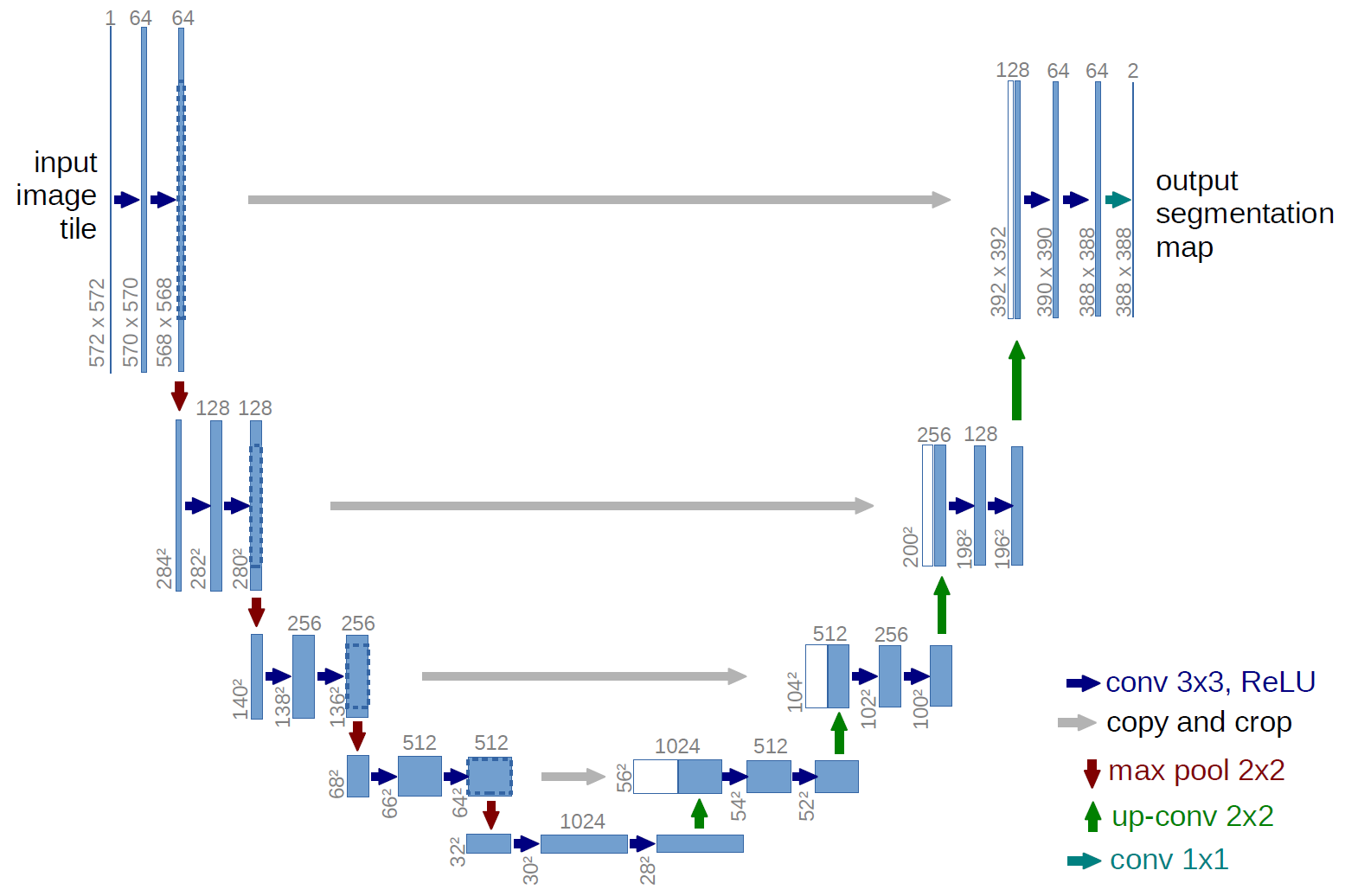
I build myself a Unet accordingly to the original Unet paper with input 564x564 RGB and smaller output segmentation map: https://github.com/CaipiDE/unet_mirror
I also implemented the mirroring strategy from the paper. So given the fact that I wanted to have a segmentation mask as big as my input, my mirror_extrapolate algorithm mirrors each side with 98px. As a result I now insert a 756x756 input (image with mirroring sides) which results in a 564x564 segmentation map, perfect
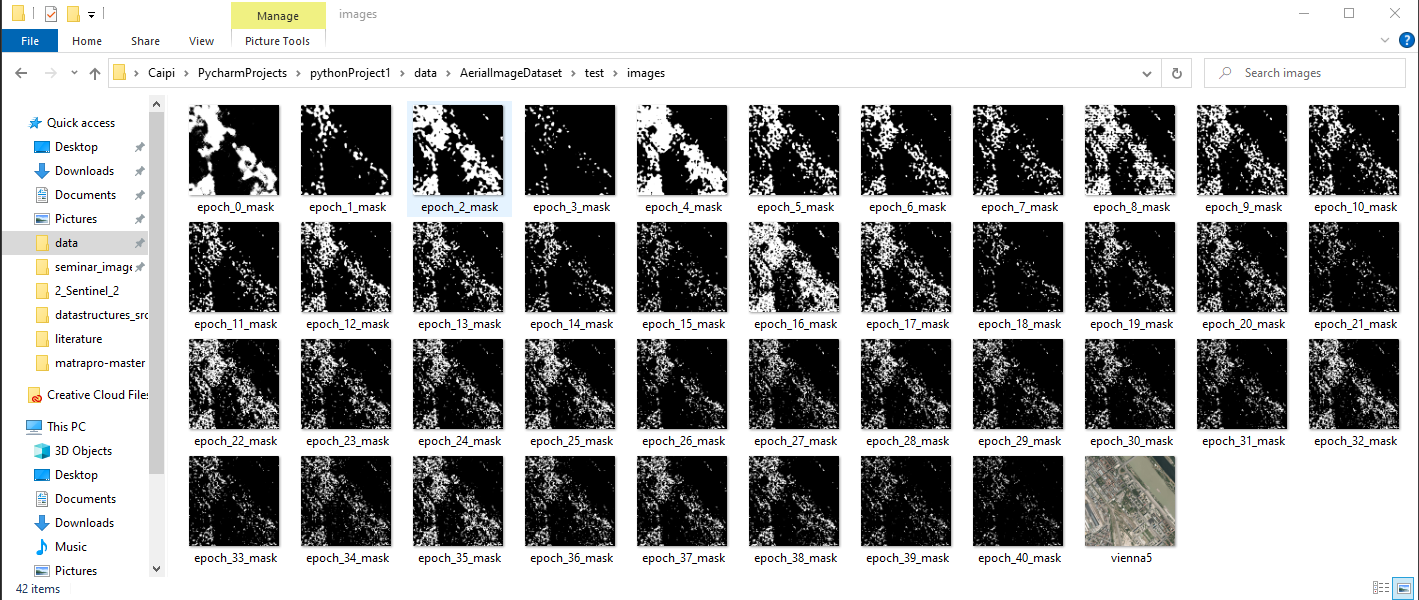
I testet it on the inria satellite imagary labeling dataset for building detection and was surprised how good it looked after just the first epoch!
But with increasing epochs, the map just literally disappears? The segmented objects have no sharp edges and are just some wobbely floating random points (not complete random but you get the point)…
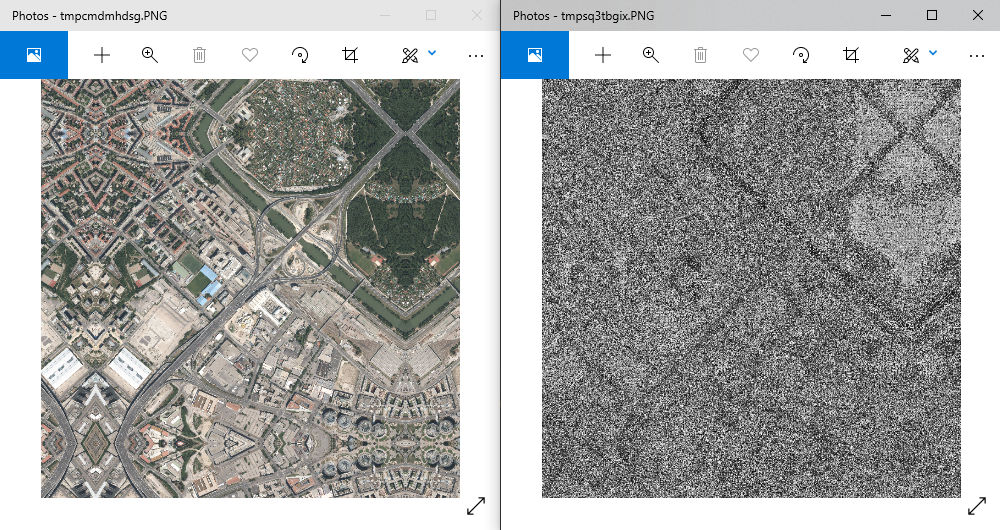
The center image is the mask while the right one is the prediction (I used your model). So, I believe it is drawing now only the edges (and thus looks like the prediction is disappeared ?).
Loss is fixed now, I guess your not supposed to mix torchvision transforms with albumentation transforms, anyway, loss is not slightly positive but never decreases and I think following is the problem now:
Left side the input data 756x756, right side the prediction in first iteration 564x564, first image. The prediction is still mirrowed at all sides (top is the most visible)… But how is this possible thus my model is never resizing but always cropping and uses no padding? Of course the ground truth is not mirrowed but has the same size of the prediction…
EDIT Wait I am talking crap sorry, I am resizing in the model, that must be the solution for that… I will crop now and update you guys.
Fixed it, my mistake. Learn: Do not mix albumentations with torchvision transforms for whatever reason…