Hi,
You are right. When you are using distributions from torch.distribution package, you are doing fine by using torch.distribution.kl_divergence. But if you want to get kl by passing two tensors obtain elsewhere, you can do following approach:
@Rojin I have posted this on your thread actually.
This is the kl between two arbitrary layers.
Just be aware that the input a must should contain log-probabilities and the target b should contain probability.
https://pytorch.org/docs/stable/nn.functional.html?highlight=kl_div#kl-div
By the way, PyTorch use this approach:
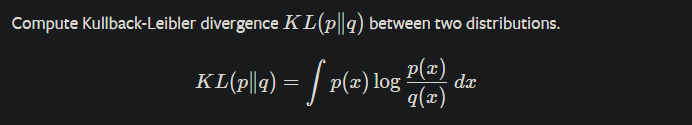
https://pytorch.org/docs/stable/distributions.html?highlight=kl_div#torch.distributions.kl.kl_divergence
Good luck
Nik