I am trying to train a simple GAN using distributed data parallel. This is my complete code that creates a model, data loader, initializes the process and run it.
The only output I get is of the first epoch
Epoch: 1 Discriminator Loss: 0.013536 Generator Loss: 0.071964 D(x): 0.724387 D(G(z)): 0.316473 / 0.024269
My code file below for your reference:
import os
import numpy as np
import torch
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
from matplotlib import pyplot as plt
import seaborn as sns
from torchvision.utils import make_grid
from torchvision import datasets
import torchvision.utils as vutils
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
import torch.multiprocessing as mp
import time
from torchvision.utils import save_image
from torch.utils.data.distributed import DistributedSampler
import argparse
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--ex', default="test", type=str, help='name')
parser.add_argument('--resume', '-r', action='store_true',
help='resume from checkpoint')
args = parser.parse_args()
path = './archive'
os.path.exists(path)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(100, 64 * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(64 * 8),
nn.ReLU(True),
nn.ConvTranspose2d(64 * 8, 64 * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.ReLU(True),
nn.ConvTranspose2d(64 * 4, 64 * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.ReLU(True),
nn.ConvTranspose2d(64 * 2, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 64 * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64 * 2, 64 * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64 * 4, 64 * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64 * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
def unnorm(images, means, stds):
means = torch.tensor(means).reshape(1,3,1,1)
stds = torch.tensor(stds).reshape(1,3,1,1)
return images*stds+means
def show_batch(data_loader):
for images, labels in data_loader:
fig, ax = plt.subplots(figsize=(15, 15))
ax.set_xticks([]); ax.set_yticks([])
unnorm_images = unnorm(images, *norm)
ax.imshow(make_grid(unnorm_images[:batch_size], nrow=8).permute(1, 2, 0).clamp(0,1))
break
def example(rank, world_size):
# create default process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Create Data loader
torch.cuda.set_device(rank)
norm=((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
batch_size = 64
image_size = 64
epochs = 5
transf = transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize(*norm,inplace=True),
])
dataset = datasets.ImageFolder(root=path,transform=transf)
train_sampler = DistributedSampler(dataset=dataset,num_replicas=2,rank=rank)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, sampler=train_sampler, num_workers=0,pin_memory = True)
# print(len(dataloader))
# create local Discriminator model
model = nn.Linear(10, 10).to(rank)
modelD = Discriminator()
modelD.to(rank)
modelD.apply(weights_init)
# create local Generator model
modelG = Generator()
modelG.to(rank)
modelG.apply(weights_init)
# construct DDP model
# ddp_model = DDP(model, device_ids=[rank])
ddp_modelD = DDP(modelD, device_ids=[rank])
ddp_modelG = DDP(modelG, device_ids=[rank])
real_label = 1.
fake_label = 0.
fixed_noise = torch.randn(64, 100, 1, 1, device=rank)
# define loss function and optimizer
criterion = nn.BCELoss()
optimizerD = optim.Adam(ddp_modelD.parameters(), lr=0.0001, betas=(0.5, 0.999))
optimizerG = optim.Adam(ddp_modelG.parameters(), lr=0.0001, betas=(0.5, 0.999))
# optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
img_list = []
G_losses, D_losses = [], []
total = 0
if rank == 0:
sample_dir = './generated'+str(args.ex)
os.makedirs(sample_dir, exist_ok=True)
# iterate over epochs
for epoch in range(epochs):
g_loss = 0.0
d_loss = 0.0
D_x = 0.0
D_G_z1 = 0.0
D_G_z2 = 0.0
calc_time = 0.0
dataloadingtime_start = time.monotonic ()
for i, data in enumerate(dataloader, 0):
# t0 = time.monotonic()
ddp_modelD.zero_grad()
real_cpu = data[0].to(rank)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=rank)
# Discriminator start
# dis_start = time.monotonic()
output = ddp_modelD(real_cpu).view(-1)
errD_real = criterion(output, label)
errD_real.backward()
D_x += output.mean().item()
noise = torch.randn(b_size, 100, 1, 1, device=rank)
fake = ddp_modelG(noise)
label.fill_(fake_label)
output = ddp_modelD(fake.detach()).view(-1)
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 += output.mean().item()
errD = errD_real + errD_fake
optimizerD.step()
#Discriminator end
# dis_end = time.monotonic()
# avg_d_time += (dis_end - dis_start)
#Generator start
# gen_start = time.monotonic()
ddp_modelG.zero_grad()
label.fill_(real_label)
output = ddp_modelD(fake).view(-1)
errG = criterion(output, label)
errG.backward()
D_G_z2 += output.mean().item()
optimizerG.step()
# gen_end = time.monotonic()
#Generator end
# avg_g_time += (gen_end - gen_start)
g_loss += errG.item()
d_loss += errD.item()
total += b_size
# t1 = time.monotonic()
# calc_time += (t1-t0)
if rank == 0:
avg_g_loss = g_loss / total
G_losses.append(avg_g_loss)
avg_d_loss = d_loss / total
D_losses.append(avg_d_loss)
avg_D_x = D_x / len(dataloader)
avg_D_G_z1 = D_G_z1 / len(dataloader)
avg_D_G_z2 = D_G_z2 / len(dataloader)
print('Epoch: {} \tDiscriminator Loss: {:.6f} \tGenerator Loss: {:.6f} \tD(x): {:.6f} \tD(G(z)): {:.6f} / {:.6f}'.format(
epoch + 1,
avg_d_loss,
avg_g_loss,
avg_D_x,
avg_D_G_z1,
avg_D_G_z2
))
with torch.no_grad():
fake = ddp_modelG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(unnorm(fake, *norm), padding=2, normalize=True))
fake_fname = 'generated-images-{0:0=4d}.png'.format(epoch+1)
save_image(unnorm(fake, *norm), os.path.join(sample_dir, fake_fname), nrow=8)
if rank == 0:
torch.save(ddp_modelG.state_dict(), './'+str(args.ex)+'G.pth')
torch.save(ddp_modelD.state_dict(), './'+str(args.ex)+'D.pth')
print('Finished Training')
end = time.monotonic()
plt.figure(figsize=(20,12))
plt.plot(G_losses,label="Generator")
plt.plot(D_losses,label="Discriminator")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.savefig(str(args.ex)+'_GDLoss.png')
plt.show()
import matplotlib.animation as animation
fig = plt.figure(figsize=(8, 8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list[::6]]
ani = animation.ArtistAnimation(fig, ims, interval=250, repeat_delay=250, blit=True)
f = './'+str(args.ex)+'animation.gif'
writergif = animation.PillowWriter(fps=30)
ani.save(f, writer=writergif)
plt.figure(figsize=(20,12))
plt.plot(G_losses,label="Generator")
plt.plot(D_losses,label="Discriminator")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.savefig(str(args.ex)+'_GDLoss.png')
plt.show()
import matplotlib.animation as animation
fig = plt.figure(figsize=(8, 8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list[::6]]
ani = animation.ArtistAnimation(fig, ims, interval=250, repeat_delay=250, blit=True)
f = './'+str(args.ex)+'animation.gif'
writergif = animation.PillowWriter(fps=30)
ani.save(f, writer=writergif)
# def init_process(rank, size, fn, backend='nccl'):
# """ Initialize the distributed environment. """
# os.environ['MASTER_ADDR'] = '127.0.0.1'
# os.environ['MASTER_PORT'] = '29500'
# dist.init_process_group(backend, rank=rank, world_size=size)
# fn(rank, size)
def main():
world_size = 2
# size = 2
# processes = []
# mp.set_start_method("spawn")
# for rank in range(size):
# p = mp.Process(target=init_process, args=(rank, size, example))
# p.start()
# print("Process started for: "+str(rank))
# processes.append(p)
# for p in processes:
# p.join()
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
# Environment variables which need to be
# set when using c10d's default "env"
# initialization mode.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29501"
start = time.monotonic
main()
end = time.monotonic
# train_time = end-start
print("Time taken for distributed training over 200 epochs: ", end-start)
dist.destroy_process_group()
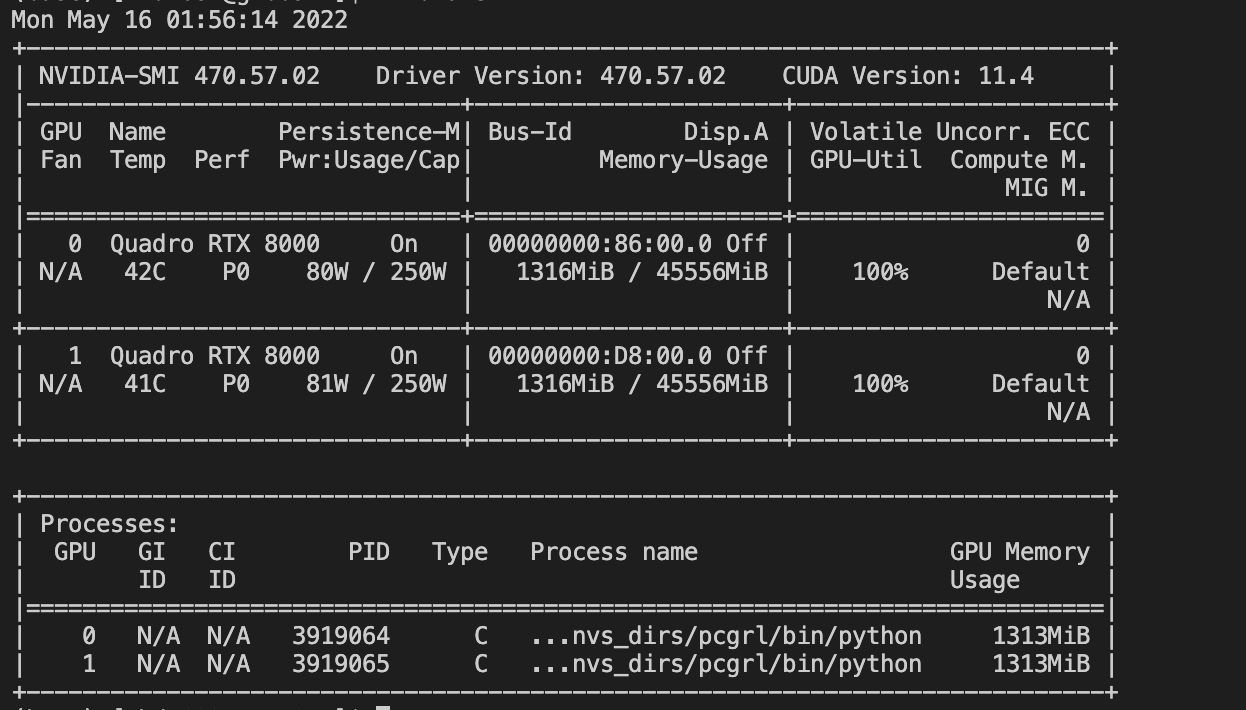
nvidia-smi gives me this output.
You can simply run the code using
python distdataparalleldcgan.py --ex test
I am kind of clueless as to what might be going wrong as there are no error outputs ?