Apologies if this is a mess, I’m quite new to PyTorch.
I’m trying to implement the algorithms from this paper:
And I’ve started with this codebase:
Which has simplified the policy gradient algorithm significantly.
Just so you don’t have to click through here is the algorithm:
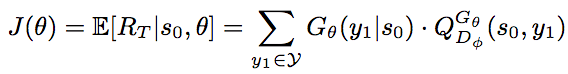
Basically J is the reward function, summing over the length of the sequence multiply the probability of getting the selected token by the reward of a Monte Carlo estimate of the reward for a discriminator for a sequence selecting that token.
However, I’m having an issue with the automated gradient and I’m not familiar enough to understand what has gone wrong.
I’ll post my attempt at this calculation but if there is anything else I can do to make this post more helpful please let me know!
for batch in range(num_batches):
sample_logits, sample = gen.sample(BATCH_SIZE*2) # 64 works best
inp, target = helpers.prepare_generator_batch(sample, start_letter=START_LETTER, gpu=CUDA)
rewards = torch.zeros(BATCH_SIZE * 2, MAX_SEQ_LEN)
for i in range(MAX_SEQ_LEN -2, MAX_SEQ_LEN):
partial_rewards = torch.zeros(BATCH_SIZE*2)
trimmed = Variable(sample.resize_(BATCH_SIZE*2, i+1))
for j in range(ROLLOUT_NUM):
rollout = gen.rollout(trimmed)
partial_rewards = partial_rewards + dis.batchClassify(rollout).data
partial_rewards = partial_rewards / ROLLOUT_NUM
rewards[:, i] = partial_rewards
sample_log_probs = Variable(torch.sum(sample_logits * one_hot(Variable(sample), VOCAB_SIZE).data, 1).log()
weighted_rewards = sample_log_probs * rewards
reward = Variable(torch.sum(torch.sum(weighted_rewards, 0), 0))
gen_opt.zero_grad()
reward.backward()
gen_opt.step()
And the error I’m getting:
RuntimeError: element 0 of variables does not require grad and does not have a grad_fn
I’ve searched enough to know that it’s having a hard time connecting my loss to the network layers.
For completeness sake here is the (working) loss code from the repository I started with:
batch_size, seq_len = inp.size()
inp = inp.permute(1, 0) # seq_len x batch_size
target = target.permute(1, 0) # seq_len x batch_size
h = self.init_hidden(batch_size)
loss = 0
for i in range(seq_len):
out, h = self.forward(inp[i], h)
# TODO: should h be detached from graph (.detach())?
for j in range(batch_size):
loss += -out[j][target.data[i][j]]*reward[j] # log(P(y_t|Y_1:Y_{t-1})) * Q
return loss/batch_size
And where it’s called:
for batch in range(num_batches):
s = gen.sample(BATCH_SIZE*2) # 64 works best
inp, target = helpers.prepare_generator_batch(s, start_letter=START_LETTER, gpu=CUDA)
rewards = dis.batchClassify(target)
gen_opt.zero_grad()
pg_loss = gen.batchPGLoss(inp, target, rewards)
pg_loss.backward()
gen_opt.step()