Hi all,
I want to build perceptual loss for video, it means that my loss contain a pre trained net (in my work im thinking of using resnet 3D which trained for video recognition task), and i want to pass my generated video and the real video through the net, and take the output of it in some layers (i.e after layer3, layer5… for each video).
i know that in the package “models” in pytorch i can load specific pre trained models, and using the features function on the input. like this for example:
self.vggnet=models.vgg16(pretrained=True).cuda()
for i in range(id_max):
x = self.vggnet.featuresi //z is the input of the net
I tried to use “features” on my 3D resnet but its not working. does anyone know how to use some layers? instead of changing the forward function of the model…
this is the way i load it
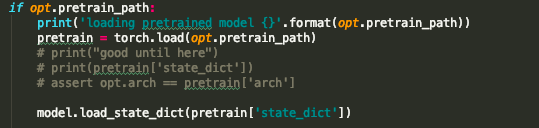
this is where i defined the net
