Hi, I am implementing a variational autoencoder. I am using the MNIST database.
I can’t get a reconstruction of the input images.
This is my implementation:
import torch
from torchvision.datasets import ImageFolder
from torchvision import transforms
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
from torchvision.utils import save_image
import argparse
import matplotlib as plt
class VAE(nn.Module):
def __init__(self, inp_s, conv_kernel_size1, conv_kernel_size2):
super(VAE, self).__init__()
self.no=20
self.n1=3
self.n2=10
self.n3=2
self.padding=0
self.stride=1
self.size_out_conv1=int(((inp_s[2]-conv_kernel_size1-2*self.padding)/self.stride)+1)
self.size_out_conv2=int(((self.size_out_conv1-conv_kernel_size2-2*self.padding)/self.stride)+1)
self.conv1=nn.Conv2d(self.n1, self.n2, kernel_size=conv_kernel_size1) #3->10
self.conv21=nn.Conv2d(self.n2, self.n3, kernel_size=conv_kernel_size2) #10->2
self.conv22=nn.Conv2d(self.n2, self.n3, kernel_size=conv_kernel_size2) #10->2
self.deconv1=nn.ConvTranspose2d(self.n2, self.n1, kernel_size=conv_kernel_size1) #10->3
self.deconv2=nn.ConvTranspose2d(self.n3, self.n2, kernel_size=conv_kernel_size2) #2->10
self.fc11=nn.Linear(self.size_out_conv2*self.size_out_conv2, self.no)
self.fc12=nn.Linear(self.size_out_conv2*self.size_out_conv2, self.no)
self.fc21=nn.Linear(self.no, self.size_out_conv2*self.size_out_conv2)
def encoder(self, x):
x=self.conv1(x)
x=F.relu(x)
moy=self.conv21(x)
variance=self.conv22(x)
return moy, variance
def decoder(self, x):
x=self.deconv2(x)
x=F.relu(x)
x=self.deconv1(x)
x=F.relu(x)
return x
def reparameterise(self, mu, var):
std=var.mul(0.5).exp_()
epsilon=Variable(std.data.new(std.size()).normal_())
return epsilon.mul(std).add_(mu)
def forward(self, x):
mu,var=self.encoder(x)
z=self.reparameterise(mu, var)
x=self.decoder(z)
return x, mu, var
def loss_fct(x, x_rec, mu, var):
reconstruction_loss=nn.MSELoss()
ER=reconstruction_loss(x_rec, x)
KL=-0.5*torch.sum(1 + var - mu.pow(2) - var.exp())
return ER + KL
def train(train_dl, inp, out1, model):
optimizer=torch.optim.Adam(model.parameters(), lr=args.learning_rate)
model.train()
train_loss=0.0
for idx, (data, label) in enumerate(train_dl):
data, label= Variable(data), Variable(label)
data = data.to(device)
out, mu, var=model(data)
loss=loss_fct(data, out, mu, var)
train_loss+=loss.item()
model.zero_grad()
loss.backward()
optimizer.step()
save_image(data[0], inp)
save_image(out[0], out1)
av_loss= train_loss / len(train_dl.dataset)
return mu, var, av_loss
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='VAE MNIST')
parser.add_argument('-bs','--batch-size', type=int, default=5, metavar='',
help='input batch size for training (default: 5)')
parser.add_argument('-ep','--epochs', type=int, default=900, metavar='',
help='number of epochs to train (default: 10)')
parser.add_argument('-lr','--learning-rate', type=float, default=0.0000001, metavar='',
help='learning rate (default: 0.001)')
parser.add_argument('-oimg','--output-img', type=str, default='/home/zaianir/Documents/out/output12.png', metavar='',
help='output image (default: output12.png)')
parser.add_argument('-iimg','--input-img', type=str, default='/home/zaianir/Documents/out/input12.png', metavar='',
help='input image (default: input12.png)')
parser.add_argument('-outp','--output', type=str, default='/home/zaianir/Documents/out/out.txt', metavar='',
help='output file (default: out.txt)')
args = parser.parse_args()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform1=transforms.Compose([transforms.ToTensor()])
train1=ImageFolder("/home/zaianir/Téléchargements/MNIST/training", transform1)
train_dl=torch.utils.data.DataLoader(train1, batch_size=args.batch_size, shuffle=True)
data , target = next(iter(train_dl))
inp_s=data.shape
model=VAE(inp_s, 5, 5).to(device)
with open(args.output, 'w') as f:
loss_tr = []
for epoch in range(1,args.epochs+1):
mu, var, loss_train= train(train_dl, args.input_img, args.output_img, model)
loss_tr.append(loss_train)
plt.pyplot.figure(1)
plt.pyplot.xlabel("epoch")
plt.pyplot.ylabel("loss")
plt.pyplot.plot(loss_tr)
Here is one of the input images I want to reconstruct:
![]()
Here is the reconstructed output image:
![]()
And here is a plot of the loss function:
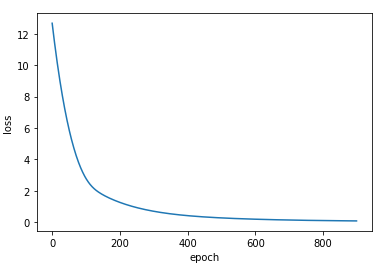
I tried different values of learning rate and batch size but I always get the same output image.
Can you please help me figure out why I can’t get a reconstruction of the input image.