Hi Sir, I Have a similar error but the .py files are different:
the code has been taken from GitHub: GitHub - Leo-Q-316/ImGAGN: Imbalanced Network Embedding vi aGenerative Adversarial Graph Networks
and the data had been transformed as it says in GitHub. The only problem I faces in the features.cora part.
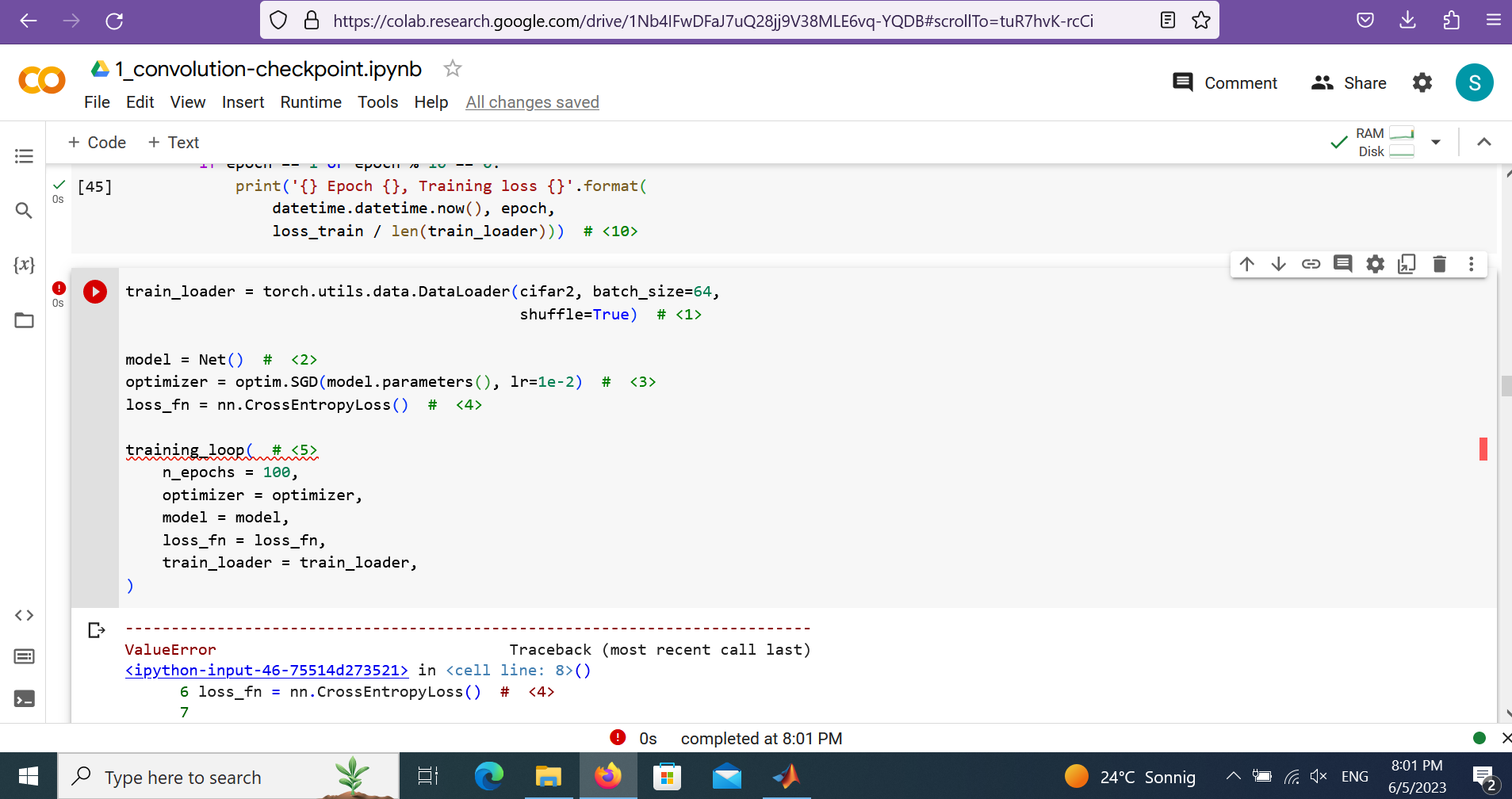
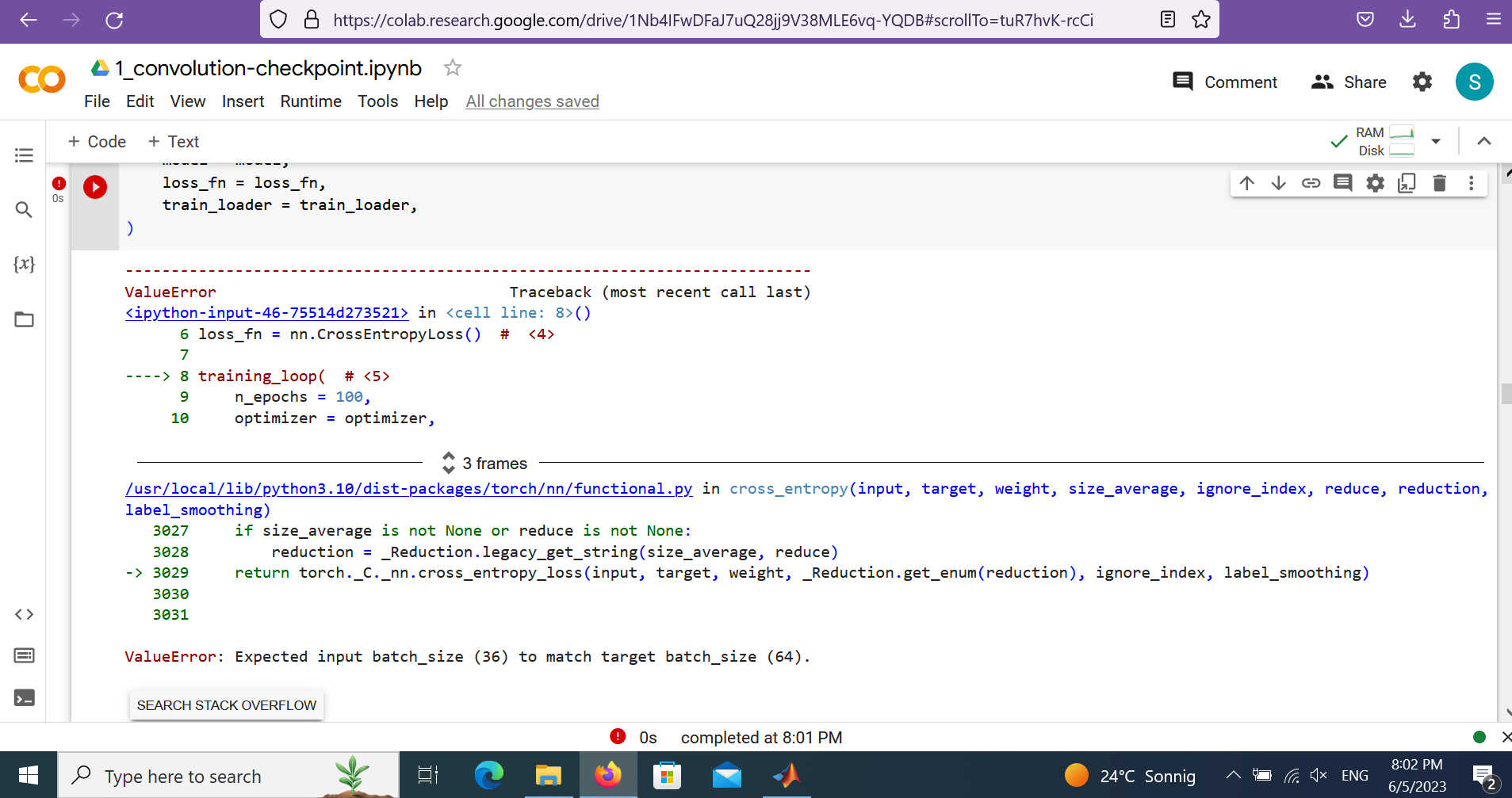
so I have this error in the following code: ValueError: Expected input batch_size (18) to match target batch_size (15).
from __future__ import division
from __future__ import print_function
import time
import argparse
import numpy as np
import scipy.sparse as sp
import torch
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from utils import load_data, accuracy, add_edges
from models import GCN
from models import Generator
# Training settings
parser = argparse.ArgumentParser()
parser.add_argument('--no-cuda', action='store_true', default=False,
help='Disables CUDA training.')
parser.add_argument('--fastmode', action='store_true', default=False,
help='Validate during training pass.')
parser.add_argument('--seed', type=int, default=42, help='Random seed.')
parser.add_argument('--epochs', type=int, default=100,
help='Number of epochs to train.')
parser.add_argument('--hidden', type=int, default=128,
help='Number of hidden units.')
parser.add_argument('--dropout', type=float, default=0.5,
help='Dropout rate (1 - keep probability).')
parser.add_argument('--epochs_gen', type=int, default=10,
help='Number of epochs to train for gen.')
parser.add_argument('--ratio_generated', type=float, default=1,
help='ratio of generated nodes.')
parser.add_argument('--dataset', choices=['cora', 'citeseer','pubmed', 'dblp', 'wiki'], default='cora')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
dataset = args.dataset
path = "../Dataset/" + dataset+"/"
if dataset=='wiki':
num = 3
else:
num = 10
# Specfic Parameters to get the best result
if dataset=='wiki':
lr=0.001
elif dataset=='dblp':
lr=0.0009
else:
lr=0.01
if dataset == 'cora':
weight_decay = 0.0008
elif dataset == 'citeseer':
weight_decay = 0.0005
elif dataset == 'pubmed':
weight_decay = 0.00008
elif dataset == 'dblp':
weight_decay = 0.003
elif dataset == 'wiki':
weight_decay = 0.0005
def train(features, adj):
global max_recall, test_recall, test_f1, test_AUC, test_acc, test_pre
model.train()
optimizer.zero_grad()
output, output_gen, output_AUC = model(features, adj)
labels_true = torch.cat((torch.LongTensor(num_real).fill_(0), torch.LongTensor(num_false).fill_(1)))
if args.cuda:
labels_true=labels_true.cuda()
loss_dis = - euclidean_dist(features[minority], features[majority]).mean()
loss_train = F.nll_loss(output[idx_train], labels[idx_train]) \
+ F.nll_loss(output_gen[idx_train], labels_true) \
+loss_dis
loss_train.backward()
optimizer.step()
if not args.fastmode:
model.eval()
output, output_gen, output_AUC = model(features, adj)
recall_val, f1_val, AUC_val, acc_val, pre_val = accuracy(output[idx_val], labels[idx_val], output_AUC[idx_val])
recall_train, f1_train, AUC_train, acc_train, pre_train = accuracy(output[idx_val], labels[idx_val], output_AUC[idx_val])
if max_recall < (recall_val + acc_val)/2:
output, output_gen, output_AUC = model(features, adj)
recall_tmp, f1_tmp, AUC_tmp, acc_tmp, pre_tmp = accuracy(output[idx_test], labels[idx_test], output_AUC[idx_test])
test_recall = recall_tmp
test_f1 = f1_tmp
test_AUC = AUC_tmp
test_acc = acc_tmp
test_pre = pre_tmp
max_recall = (recall_val + acc_val)/2
return recall_val, f1_val, acc_val, recall_train, f1_train, acc_train
def euclidean_dist(x, y):
m, n = x.size(0), y.size(0)
xx = torch.pow(x, 2).sum(1, keepdim=True).expand(m, n)
yy = torch.pow(y, 2).sum(1, keepdim=True).expand(n, m).t()
dist = xx + yy
dist.addmm_(1, -2, x, y.t())
dist = dist.clamp(min=1e-12).sqrt() # for numerical stability
return dist
# ratio_arr = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
# for ratio in ratio_arr:
adj, adj_real, features, labels, idx_temp, idx_test, generate_node, minority, majority, minority_all = load_data(args.ratio_generated, path=path, dataset=dataset)
# Model and optimizer
model = GCN(nfeat=features.shape[1],
nhid=args.hidden,
nclass=labels.max().item() + 1,
dropout=args.dropout,
generate_node= generate_node,
min_node = minority)
optimizer = optim.Adam(model.parameters(),lr=lr, weight_decay=weight_decay)
# num_real = features.shape[0]
num_false = labels.shape[0]- features.shape[0] #diff bw lengths of first row
print(num_false)
model_generator = Generator(minority_all.shape[0])
optimizer_G = torch.optim.Adam(model_generator.parameters(),
lr=lr, weight_decay=weight_decay)
max_recall = 0
test_recall = 0
test_f1 = 0
test_AUC = 0
test_acc=0
test_pre =0
if args.cuda:
model.cuda()
features = features.cuda()
adj = adj.cuda()
labels = labels.cuda()
idx_temp = idx_temp.cuda()
idx_test = idx_test.cuda()
model_generator.cuda()
for epoch_gen in range(args.epochs_gen):
part = epoch_gen % num
range_val_maj = range(int(part*len(majority)/num), int((part+1)*len(majority)/num))
range_val_min = range(int(part * len(minority) / num), int((part + 1) * len(minority) / num))
range_train_maj = list(range(0,int(part*len(majority)/num)))+ list(range(int((part+1)*len(majority)/num),len(majority)))
range_train_min = list(range(0,int(part*len(minority)/num)))+ list(range(int((part+1)*len(minority)/num),len(minority)))
idx_val = torch.cat((majority[range_val_maj], minority[range_val_min]))
idx_train = torch.cat((majority[range_train_maj], minority[range_train_min]))
idx_train = torch.cat((idx_train, generate_node))
num_real = features.shape[0] - len(idx_test) -len(idx_val)
# Train model
model_generator.train()
optimizer_G.zero_grad()
z = Variable(torch.FloatTensor(np.random.normal(0, 1, (generate_node.shape[0], 100))))
if args.cuda:
z=z.cuda()
adj_min = model_generator(z)
gen_imgs1 = torch.mm(F.softmax(adj_min[:,0:minority.shape[0]], dim=1), features[minority])
gen_imgs1_all = torch.mm(F.softmax(adj_min, dim=1), features[minority_all])
matr = F.softmax(adj_min[:,0:minority.shape[0]], dim =1).data.cpu().numpy()
pos=np.where(matr>1/matr.shape[1])
adj_temp = sp.coo_matrix((np.ones(pos[0].shape[0]),(generate_node[pos[0]].numpy(), minority_all[pos[1]].numpy())),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32)
adj_new = add_edges(adj_real, adj_temp)
if args.cuda:
adj_new=adj_new.cuda()
t_total = time.time()
# model.eval()
output, output_gen, output_AUC = model(torch.cat((features, gen_imgs1.data),0), adj)
labels_true = torch.LongTensor(num_false).fill_(0)
labels_min = torch.LongTensor(num_false).fill_(1)
if args.cuda:
labels_true = labels_true.cuda()
labels_min = labels_min.cuda()
g_loss = F.nll_loss(output_gen[generate_node], labels_true) \
+ F.nll_loss(output[generate_node], labels_min) \
+ euclidean_dist(features[minority], gen_imgs1).mean()
print(output[idx_train].size())
print(labels[idx_train].size())
print(output_gen[idx_train].size())
print(labels_true.size())
print(num_false)
print(num_real)
g_loss.backward()
optimizer_G.step()
for epoch in range(args.epochs):
recall_val, f1_val, acc_val, recall_train, f1_train, acc_train = train(torch.cat((features, gen_imgs1.data.detach()),0), adj_new)
print("Epoch:", '%04d' % (epoch_gen + 1),
"train_recall=", "{:.5f}".format(recall_train), "train_f1=", "{:.5f}".format(f1_train),"train_acc=", "{:.5f}".format(acc_train),
"val_recall=", "{:.5f}".format(recall_val), "val_f1=", "{:.5f}".format(f1_val),"val_acc=", "{:.5f}".format(acc_val))
print("Test Recall: ", test_recall)
print("Test Accuracy: ", test_acc)
print("Test F1: ", test_f1)
print("Test precision: ", test_pre)
print("Test AUC: ", test_AUC)
I can see that the target_batch size = num_Real+num_false where :
features = sp.csr_matrix(idx_features_labels[:, 0:-1], dtype=np.float32) #reverse order of features cora ndarray
labels = idx_features_labels[:, -1]
Ps this is required for a group project which is due on 24th so I would be grateful if u could help out