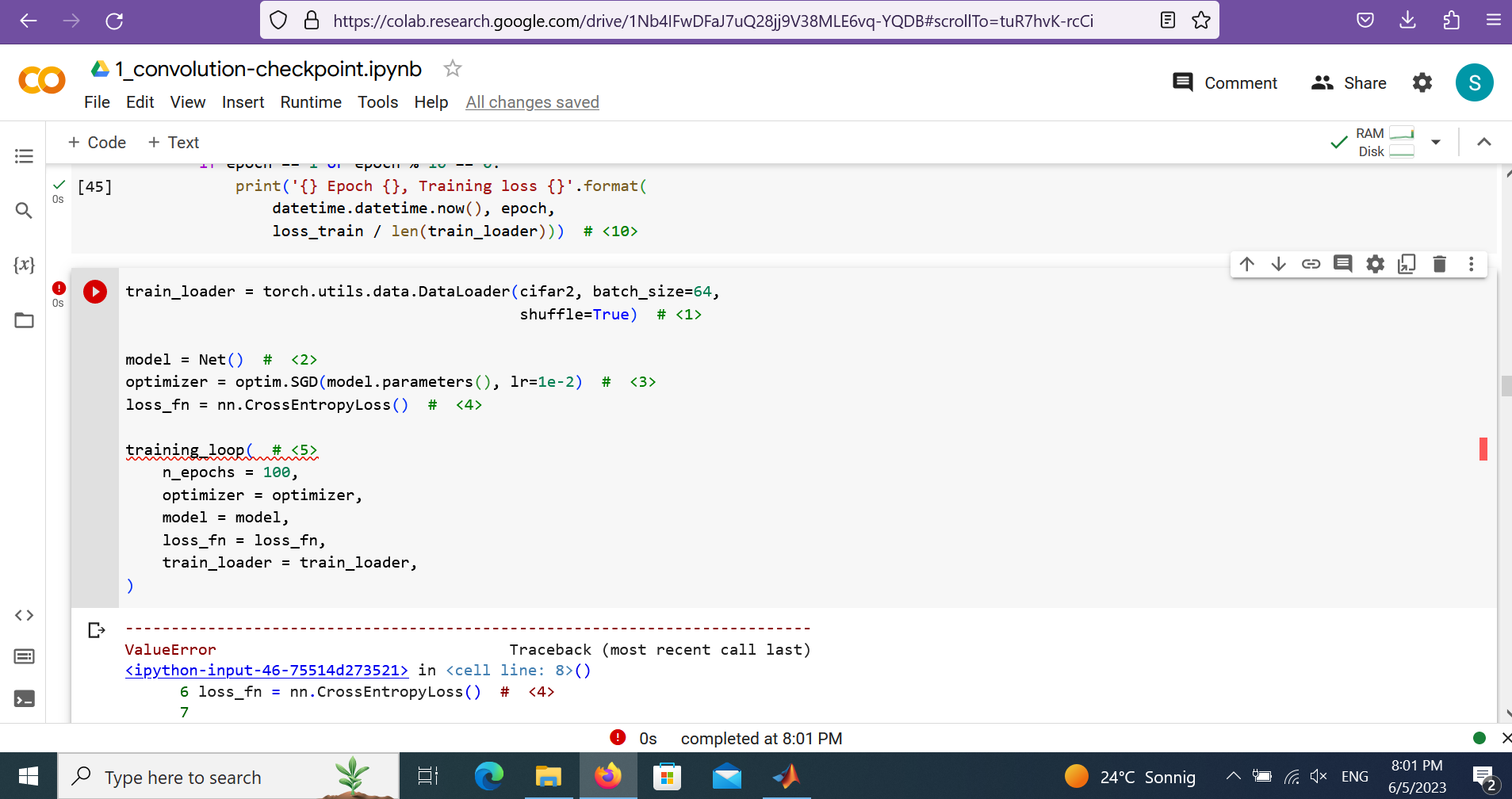
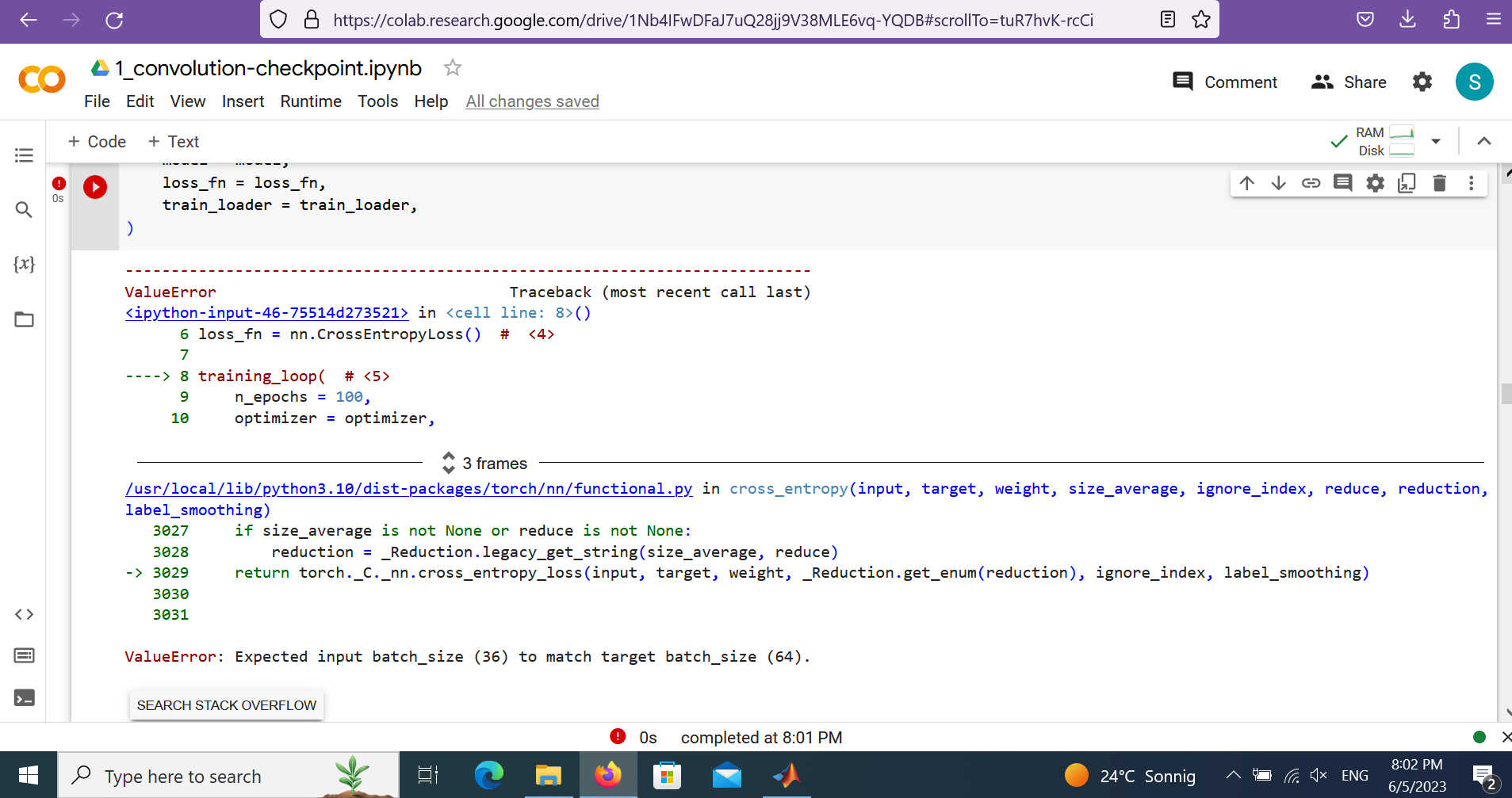
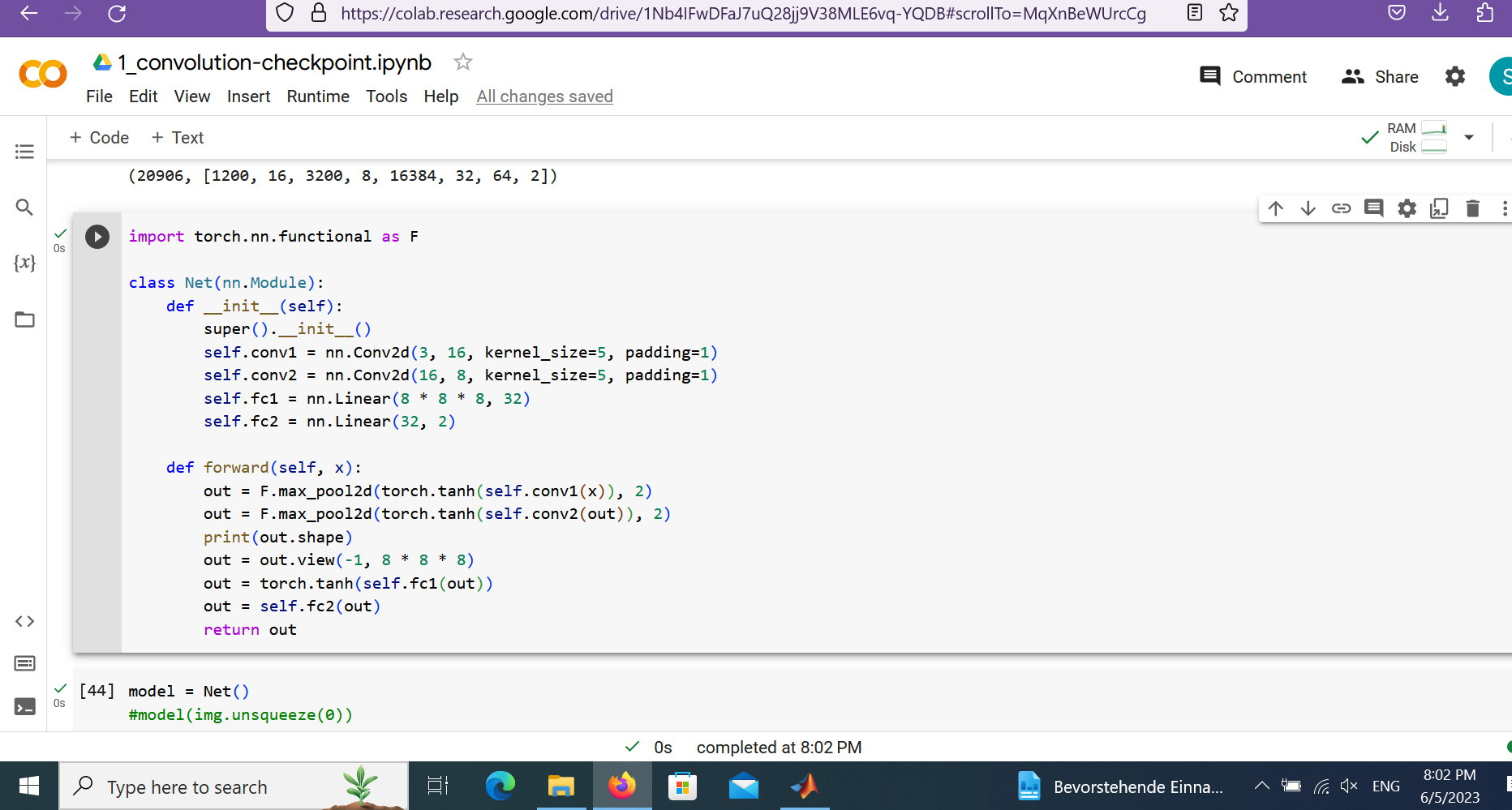
Hi @ptrblck , I got similar error,> /python3.8/site-packages/torch/nn/functional.py", line 3029, in cross_entropy
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
ValueError: Expected input batch_size (1022) to match target batch_size (1)
I found the input tensor is wright, but somehow in the crossentropy calculating, the input batch_size and output batch_size, miss-matched. Thanks a lot if you could help.
the log is quite long:
Installed CUDA version 11.4 does not match the version torch was compiled with 11.7 but since the APIs are compatible, accepting this combination
Using /root/.cache/torch_extensions/py38_cu117 as PyTorch extensions root...
Installed CUDA version 11.4 does not match the version torch was compiled with 11.7 but since the APIs are compatible, accepting this combination
Using /root/.cache/torch_extensions/py38_cu117 as PyTorch extensions root...
Detected CUDA files, patching ldflags
Emitting ninja build file /root/.cache/torch_extensions/py38_cu117/cpu_adam/build.ninja...
Building extension module cpu_adam...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
ninja: no work to do.
Adam Optimizer #0 is created with AVX2 arithmetic capability.
Config: alpha=0.000020, betas=(0.900000, 0.999000), weight_decay=0.010000, adam_w=1
Adam Optimizer #0 is created with AVX2 arithmetic capability.
Config: alpha=0.000020, betas=(0.900000, 0.999000), weight_decay=0.010000, adam_w=1
[2023-07-09 16:45:23,230] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed info: version=0.9.5, git-hash=unknown, git-branch=unknown
Adam Optimizer #0 is created with AVX2 arithmetic capability.
Config: alpha=0.000020, betas=(0.900000, 0.999000), weight_decay=0.010000, adam_w=1
Adam Optimizer #0 is created with AVX2 arithmetic capability.
Config: alpha=0.000020, betas=(0.900000, 0.999000), weight_decay=0.010000, adam_w=1
[2023-07-09 16:45:23,538] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed Flops Profiler Enabled: False
[2023-07-09 16:45:23,541] [INFO] [logging.py:96:log_dist] [Rank 0] Removing param_group that has no 'params' in the client Optimizer
[2023-07-09 16:45:23,541] [INFO] [logging.py:96:log_dist] [Rank 0] Using client Optimizer as basic optimizer
[2023-07-09 16:45:23,575] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed Basic Optimizer = DeepSpeedCPUAdam
[2023-07-09 16:45:23,575] [INFO] [utils.py:54:is_zero_supported_optimizer] Checking ZeRO support for optimizer=DeepSpeedCPUAdam type=<class 'deepspeed.ops.adam.cpu_adam.DeepSpeedCPUAdam'>
[2023-07-09 16:45:23,575] [INFO] [logging.py:96:log_dist] [Rank 0] Creating fp16 ZeRO stage 3 optimizer, MiCS is enabled False, Hierarchical params gather False
[2023-07-09 16:45:23,576] [INFO] [logging.py:96:log_dist] [Rank 0] Creating torch.bfloat16 ZeRO stage 3 optimizer
[2023-07-09 16:45:23,702] [INFO] [utils.py:785:see_memory_usage] Stage 3 initialize beginning
[2023-07-09 16:45:23,703] [INFO] [utils.py:786:see_memory_usage] MA 0.04 GB Max_MA 0.8 GB CA 0.81 GB Max_CA 1 GB
[2023-07-09 16:45:23,703] [INFO] [utils.py:793:see_memory_usage] CPU Virtual Memory: used = 38.2 GB, percent = 15.2%
[2023-07-09 16:45:23,706] [INFO] [stage3.py:113:__init__] Reduce bucket size 500,000,000
[2023-07-09 16:45:23,706] [INFO] [stage3.py:114:__init__] Prefetch bucket size 50,000,000
[2023-07-09 16:45:23,808] [INFO] [utils.py:785:see_memory_usage] DeepSpeedZeRoOffload initialize [begin]
[2023-07-09 16:45:24,673] [INFO] [stage3.py:387:_setup_for_real_optimizer] optimizer state initialized
labels shape: torch.Size([2])labels shape: torch.Size([2])
input_ids shape:input_ids shape: {torch.Size([2, 512])}
{torch.Size([2, 512])}
attention_mask shape:attention_mask shape: {torch.Size([2, 512])}{torch.Size([2, 512])}
labels shape: torch.Size([2])
input_ids shape: {torch.Size([2, 512])}
attention_mask shape: {torch.Size([2, 512])}
[2023-07-09 16:45:24,851] [INFO] [utils.py:785:see_memory_usage] After initializing ZeRO optimizer
[2023-07-09 16:45:24,852] [INFO] [utils.py:786:see_memory_usage] MA 0.96 GB Max_MA 0.96 GB CA 1.74 GB Max_CA 2 GB
[2023-07-09 16:45:24,853] [INFO] [utils.py:793:see_memory_usage] CPU Virtual Memory: used = 38.32 GB, percent = 15.2%
[2023-07-09 16:45:24,853] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed Final Optimizer = DeepSpeedCPUAdam
[2023-07-09 16:45:24,853] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed using client LR scheduler
[2023-07-09 16:45:24,853] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed LR Scheduler = None
[2023-07-09 16:45:24,853] [INFO] [logging.py:96:log_dist] [Rank 0] step=0, skipped=0, lr=[2e-05], mom=[(0.9, 0.999)]
[2023-07-09 16:45:24,855] [INFO] [config.py:960:print] DeepSpeedEngine configuration:
[2023-07-09 16:45:24,855] [INFO] [config.py:964:print] activation_checkpointing_config {
"partition_activations": false,
"contiguous_memory_optimization": false,
"cpu_checkpointing": false,
"number_checkpoints": null,
"synchronize_checkpoint_boundary": false,
"profile": false
}
[2023-07-09 16:45:24,855] [INFO] [config.py:964:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}
[2023-07-09 16:45:24,855] [INFO] [config.py:964:print] amp_enabled .................. False
[2023-07-09 16:45:24,855] [INFO] [config.py:964:print] amp_params ................... False
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] autotuning_config ............ {
"enabled": false,
"start_step": null,
"end_step": null,
"metric_path": null,
"arg_mappings": null,
"metric": "throughput",
"model_info": null,
"results_dir": "autotuning_results",
"exps_dir": "autotuning_exps",
"overwrite": true,
"fast": true,
"start_profile_step": 3,
"end_profile_step": 5,
"tuner_type": "gridsearch",
"tuner_early_stopping": 5,
"tuner_num_trials": 50,
"model_info_path": null,
"mp_size": 1,
"max_train_batch_size": null,
"min_train_batch_size": 1,
"max_train_micro_batch_size_per_gpu": 1.024000e+03,
"min_train_micro_batch_size_per_gpu": 1,
"num_tuning_micro_batch_sizes": 3
}
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] bfloat16_enabled ............. True
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] checkpoint_parallel_write_pipeline False
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] checkpoint_tag_validation_enabled True
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] checkpoint_tag_validation_fail False
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] comms_config ................. <deepspeed.comm.config.DeepSpeedCommsConfig object at 0x14ebe59c75e0>
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] communication_data_type ...... None
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] compression_config ........... {'weight_quantization': {'shared_parameters': {'enabled': False, 'quantizer_kernel': False, 'schedule_offset': 0, 'quantize_groups': 1, 'quantize_verbose': False, 'quantization_type': 'symmetric', 'quantize_weight_in_forward': False, 'rounding': 'nearest', 'fp16_mixed_quantize': False, 'quantize_change_ratio': 0.001}, 'different_groups': {}}, 'activation_quantization': {'shared_parameters': {'enabled': False, 'quantization_type': 'symmetric', 'range_calibration': 'dynamic', 'schedule_offset': 1000}, 'different_groups': {}}, 'sparse_pruning': {'shared_parameters': {'enabled': False, 'method': 'l1', 'schedule_offset': 1000}, 'different_groups': {}}, 'row_pruning': {'shared_parameters': {'enabled': False, 'method': 'l1', 'schedule_offset': 1000}, 'different_groups': {}}, 'head_pruning': {'shared_parameters': {'enabled': False, 'method': 'topk', 'schedule_offset': 1000}, 'different_groups': {}}, 'channel_pruning': {'shared_parameters': {'enabled': False, 'method': 'l1', 'schedule_offset': 1000}, 'different_groups': {}}, 'layer_reduction': {'enabled': False}}
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] curriculum_enabled_legacy .... False
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] curriculum_params_legacy ..... False
[2023-07-09 16:45:24,856] [INFO] [config.py:964:print] data_efficiency_config ....... {'enabled': False, 'seed': 1234, 'data_sampling': {'enabled': False, 'num_epochs': 1000, 'num_workers': 0, 'curriculum_learning': {'enabled': False}}, 'data_routing': {'enabled': False, 'random_ltd': {'enabled': False, 'layer_token_lr_schedule': {'enabled': False}}}}
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] data_efficiency_enabled ...... False
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] dataloader_drop_last ......... False
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] disable_allgather ............ False
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] dump_state ................... False
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] dynamic_loss_scale_args ...... None
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] eigenvalue_enabled ........... False
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] eigenvalue_gas_boundary_resolution 1
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] eigenvalue_layer_name ........ bert.encoder.layer
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] eigenvalue_layer_num ......... 0
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] eigenvalue_max_iter .......... 100
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] eigenvalue_stability ......... 1e-06
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] eigenvalue_tol ............... 0.01
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] eigenvalue_verbose ........... False
[2023-07-09 16:45:24,857] [INFO] [config.py:964:print] elasticity_enabled ........... False
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] flops_profiler_config ........ {
"enabled": false,
"recompute_fwd_factor": 0.0,
"profile_step": 1,
"module_depth": -1,
"top_modules": 1,
"detailed": true,
"output_file": null
}
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] fp16_auto_cast ............... None
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] fp16_enabled ................. False
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] fp16_master_weights_and_gradients False
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] global_rank .................. 0
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] grad_accum_dtype ............. None
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] gradient_accumulation_steps .. 4
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] gradient_clipping ............ 0.0
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] gradient_predivide_factor .... 1.0
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] hybrid_engine ................ enabled=False max_out_tokens=512 inference_tp_size=1 release_inference_cache=False pin_parameters=True tp_gather_partition_size=8
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] initial_dynamic_scale ........ 1
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] load_universal_checkpoint .... False
[2023-07-09 16:45:24,858] [INFO] [config.py:964:print] loss_scale ................... 1.0
[2023-07-09 16:45:24,859] [INFO] [config.py:964:print] memory_breakdown ............. False
[2023-07-09 16:45:24,859] [INFO] [config.py:964:print] mics_hierarchial_params_gather False
[2023-07-09 16:45:24,859] [INFO] [config.py:964:print] mics_shard_size .............. -1
[2023-07-09 16:45:24,859] [INFO] [config.py:964:print] monitor_config ............... tensorboard=TensorBoardConfig(enabled=False, output_path='', job_name='DeepSpeedJobName') wandb=WandbConfig(enabled=False, group=None, team=None, project='deepspeed') csv_monitor=CSVConfig(enabled=False, output_path='', job_name='DeepSpeedJobName') enabled=False
allgather_partitions=True allgather_bucket_size=500,000,000 overlap_comm=True load_from_fp32_weights=True elastic_checkpoint=False offload_param=DeepSpeedZeroOffloadParamConfig(device='cpu', nvme_path=None, buffer_count=5, buffer_size=100,000,000, max_in_cpu=1,000,000,000, pin_memory=False) offload_optimizer=DeepSpeedZeroOffloadOptimizerConfig(device='cpu', nvme_path=None, buffer_count=4, pin_memory=False, pipeline=False, pipeline_read=False, pipeline_write=False, fast_init=False) sub_group_size=1,000,000,000 cpu_offload_param=None cpu_offload_use_pin_memory=None cpu_offload=None prefetch_bucket_size=50,000,000 param_persistence_threshold=100,000 model_persistence_threshold=sys.maxsize max_live_parameters=1,000,000,000 max_reuse_distance=1,000,000,000 gather_16bit_weights_on_model_save=True stage3_gather_fp16_weights_on_model_save=False ignore_unused_parameters=True legacy_stage1=False round_robin_gradients=False mics_shard_size=-1 mics_hierarchical_params_gather=False memory_efficient_linear=True
[2023-07-09 16:45:24,860] [INFO] [config.py:964:print] zero_enabled ................. True
[2023-07-09 16:45:24,860] [INFO] [config.py:964:print] zero_force_ds_cpu_optimizer .. True
[2023-07-09 16:45:24,860] [INFO] [config.py:964:print] zero_optimization_stage ...... 3
[2023-07-09 16:45:24,861] [INFO] [config.py:950:print_user_config] json = {
"train_batch_size": 32,
"train_micro_batch_size_per_gpu": 2,
"gradient_accumulation_steps": 4,
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"nvme_path": null
},
"offload_param": {
"device": "cpu",
"nvme_path": null
},
"stage3_gather_16bit_weights_on_model_save": true
},
"steps_per_print": inf,
"bf16": {
"enabled": true
},
"fp16": {
"enabled": false
},
"zero_allow_untested_optimizer": true
}
***** Running training *****
labels shape: torch.Size([2])
input_ids shape: {torch.Size([2, 512])}
attention_mask shape: {torch.Size([2, 512])}
Traceback (most recent call last):
File "/workspace/work00/sue-xie/llama/kyano_lora/src/main_paws.py", line 363, in <module>
Traceback (most recent call last):
File "/workspace/work00/sue-xie/llama/kyano_lora/src/main_paws.py", line 363, in <module>
Traceback (most recent call last):
File "/workspace/work00/sue-xie/llama/kyano_lora/src/main_paws.py", line 363, in <module>
main()
File "/workspace/work00/sue-xie/llama/kyano_lora/src/main_paws.py", line 316, in main
main()
File "/workspace/work00/sue-xie/llama/kyano_lora/src/main_paws.py", line 316, in main
outputs = model(**batch, use_cache=False)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
main()
File "/workspace/work00/sue-xie/llama/kyano_lora/src/main_paws.py", line 316, in main
outputs = model(**batch, use_cache=False)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
outputs = model(**batch, use_cache=False)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/deepspeed/utils/nvtx.py", line 15, in wrapped_fn
ret_val = func(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1735, in forward
return forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/deepspeed/utils/nvtx.py", line 15, in wrapped_fn
return forward_call(*args, **kwargs)ret_val = func(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/deepspeed/utils/nvtx.py", line 15, in wrapped_fn
File "/opt/conda/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1735, in forward
ret_val = func(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1735, in forward
loss = self.module(*inputs, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1538, in _call_impl
loss = self.module(*inputs, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1538, in _call_impl
loss = self.module(*inputs, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1538, in _call_impl
result = forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/peft/peft_model.py", line 575, in forward
result = forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/peft/peft_model.py", line 575, in forward
return self.base_model(
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1538, in _call_impl
result = forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/peft/peft_model.py", line 575, in forward
return self.base_model(
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1538, in _call_impl
return self.base_model(
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1538, in _call_impl
result = forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/transformers/models/llama/modeling_llama.py", line 714, in forward
result = forward_call(*args, **kwargs)
Traceback (most recent call last):
File "/opt/conda/lib/python3.8/site-packages/transformers/models/llama/modeling_llama.py", line 714, in forward
loss = loss_fct(shift_logits, shift_labels)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
result = forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/transformers/models/llama/modeling_llama.py", line 714, in forward
loss = loss_fct(shift_logits, shift_labels)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
loss = loss_fct(shift_logits, shift_labels)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/loss.py", line 1174, in forward
return forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/loss.py", line 1174, in forward
File "/workspace/work00/sue-xie/llama/kyano_lora/src/main_paws.py", line 363, in <module>
main()
return F.cross_entropy(input, target, weight=self.weight,
return forward_call(*args, **kwargs) File "/opt/conda/lib/python3.8/site-packages/torch/nn/functional.py", line 3029, in cross_entropy
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/loss.py", line 1174, in forward
File "/workspace/work00/sue-xie/llama/kyano_lora/src/main_paws.py", line 316, in main
outputs = model(**batch, use_cache=False)
return F.cross_entropy(input, target, weight=self.weight,
File "/opt/conda/lib/python3.8/site-packages/torch/nn/functional.py", line 3029, in cross_entropy
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
return F.cross_entropy(input, target, weight=self.weight,
File "/opt/conda/lib/python3.8/site-packages/torch/nn/functional.py", line 3029, in cross_entropy
File "/opt/conda/lib/python3.8/site-packages/deepspeed/utils/nvtx.py", line 15, in wrapped_fn
ret_val = func(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1735, in forward
loss = self.module(*inputs, **kwargs)
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1538, in _call_impl
result = forward_call(*args, **kwargs)
ValueError: Expected input batch_size (1022) to match target batch_size (1).
File "/opt/conda/lib/python3.8/site-packages/peft/peft_model.py", line 575, in forward
return self.base_model(
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
ValueError: Expected input batch_size (1022) to match target batch_size (1).
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1538, in _call_impl
result = forward_call(*args, **kwargs)
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
File "/opt/conda/lib/python3.8/site-packages/transformers/models/llama/modeling_llama.py", line 714, in forward
loss = loss_fct(shift_logits, shift_labels)
ValueError: Expected input batch_size (1022) to match target batch_size (1).
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/loss.py", line 1174, in forward
return F.cross_entropy(input, target, weight=self.weight,
File "/opt/conda/lib/python3.8/site-packages/torch/nn/functional.py", line 3029, in cross_entropy
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
ValueError: Expected input batch_size (1022) to match target batch_size (1).```
And My code is as below:
import evaluate
metric = evaluate.load(“accuracy”)
def evaluate(args, model, eval_dataloader, accelerator, eval_dataset):
model.eval()
losses =
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather_for_metrics(loss.repeat(args.per_device_eval_batch_size)))
logits = outputs.logits
predictions = torch.argmax(logit, dim=-1)
metric.add_batch(predictions=predictions, reference = batch["labels"])
losses = torch.cat(losses)
metric.compute()
try:
eval_loss = torch.mean(losses)
perplexity = math.exp(eval_loss)
except OverflowError:
perplexity = float("inf")
return perplexity, eval_loss,metric.compute()
from transformers import AutoTokenizer, DataCollatorWithPadding
#data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,pad_to_multiple_of=8,mlm=False)
#metric = evaluate.load(“accuracy”)
def main():
args = parse_args()
accelerator = Accelerator(log_with="wandb")
hps = {"learning_rate": args.learning_rate}
accelerator.init_trackers(args.wandb_name)
set_random_seed(args.seed)
tokenizer = LlamaTokenizer.from_pretrained(args.model_name_or_path,
fast_tokenizer=True)
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorWithPadding(tokenizer=tokenizer,pad_to_multiple_of=8,
)
# tokenizer.pad_token_id = (
# 0
# )
# tokenizer.padding_side = "left"
# tokenizer.pad_token = tokenizer.eos_token
model = create_hf_model(LlamaForCausalLM, args.model_name_or_path,
tokenizer)
peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM, inference_mode=False, r=args.lora_dim, lora_alpha=args.lora_alpha, lora_dropout=args.lora_dropout)
model = get_peft_model(model, peft_config)
with accelerator.main_process_first():
train_dataset = create_dataset(
args.local_rank, # invalid
args.data_output_path,
args.seed,
tokenizer,
args.max_seq_len,
True,
#imitation_model=args.imitation_model # invalid
)
#print(train_dataset[0])
eval_dataset = create_dataset(
args.local_rank,
args.data_output_path,
args.seed,
tokenizer,
args.max_seq_len,
False,
#imitation_model=args.imitation_model
)
accelerator.wait_for_everyone()
# DataLoaders creation:
train_dataloader = DataLoader(
train_dataset, collate_fn=data_collator,
batch_size= args.per_device_train_batch_size
)
eval_dataloader = DataLoader(
eval_dataset, collate_fn=data_collator,
batch_size= args.per_device_eval_batch_size
)
# train_dataloader = DataLoader(train_dataset,
# # collate_fn=DataCollatorForSeq2Seq(
# # tokenizer, pad_to_multiple_of=8,return_tensors="pt",padding=True
# # ),
# #data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# batch_size=args.per_device_train_batch_size)
# eval_dataloader = DataLoader(eval_dataset,
# # collate_fn=DataCollatorForSeq2Seq(
# # tokenizer,pad_to_multiple_of=8,
# # return_tensors="pt",padding=True
# # ),
# batch_size=args.per_device_eval_batch_size)
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
# New Code #
# Creates Dummy Optimizer if `optimizer` was specified in the config file else creates Adam Optimizer
optimizer_cls = (
torch.optim.AdamW
if accelerator.state.deepspeed_plugin is None
or "optimizer" not in accelerator.state.deepspeed_plugin.deepspeed_config
else DummyOptim
)
optimizer = optimizer_cls(optimizer_grouped_parameters, lr=args.learning_rate)
num_update_steps_per_epoch = math.ceil(
len(train_dataloader) / args.gradient_accumulation_steps)
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.num_train_epochs * num_update_steps_per_epoch,
)
model, train_dataloader, eval_dataloader, optimizer, lr_scheduler = accelerator.prepare(
model, train_dataloader, eval_dataloader, optimizer, lr_scheduler)
# Train!
print_rank_0("***** Running training *****", accelerator.process_index)
for epoch in range(args.num_train_epochs):
current_step = []
model.train()
for step, batch in enumerate(train_dataloader):
#sue
if step == 0:
print(f'labels shape: {batch["labels"].shape}')
print("input_ids shape:",{batch["input_ids"].shape})
print("attention_mask shape:",{batch["attention_mask"].shape})
outputs = model(**batch, use_cache=False)
train_loss = outputs.loss
accelerator.backward(train_loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
accelerator.log({"train_loss": train_loss})
accelerator.log({"lr": lr_scheduler.get_lr()[0]})
if step % 300 == 0:
print_rank_0(f"Epoch is {epoch}, Step is {step}, train_loss is {train_loss.item()}", accelerator.process_index)
ppl, eval_loss = evaluate(args, model, eval_dataloader, accelerator, eval_dataset)
if accelerator.is_main_process:
print_rank_0(f"eval_loss: {eval_loss}, ppl: {ppl}", accelerator.process_index)
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
# New Code #
# Saves the whole/unpartitioned fp16 model when in ZeRO Stage-3 to the output directory if
# `stage3_gather_16bit_weights_on_model_save` is True in DeepSpeed Config file or
# `zero3_save_16bit_model` is True in DeepSpeed Plugin.
# For Zero Stages 1 and 2, models are saved as usual in the output directory.
# The model name saved is `pytorch_model.bin`
unwrapped_model.save_pretrained(
args.output_dir,
is_main_process=accelerator.is_main_process,
save_function=accelerator.save,
state_dict=accelerator.get_state_dict(model),
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
accelerator.end_training()
if name == “main”:
main()