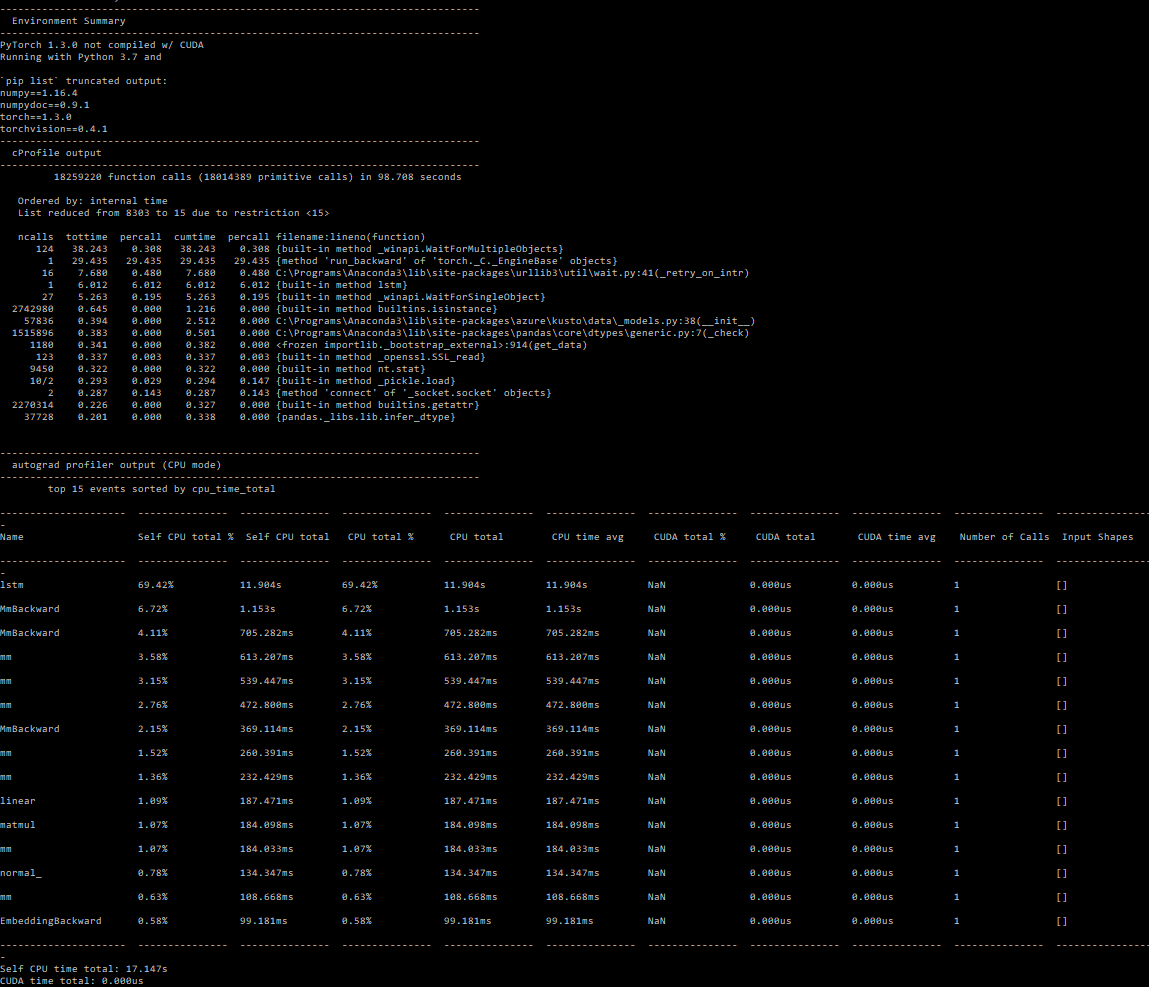
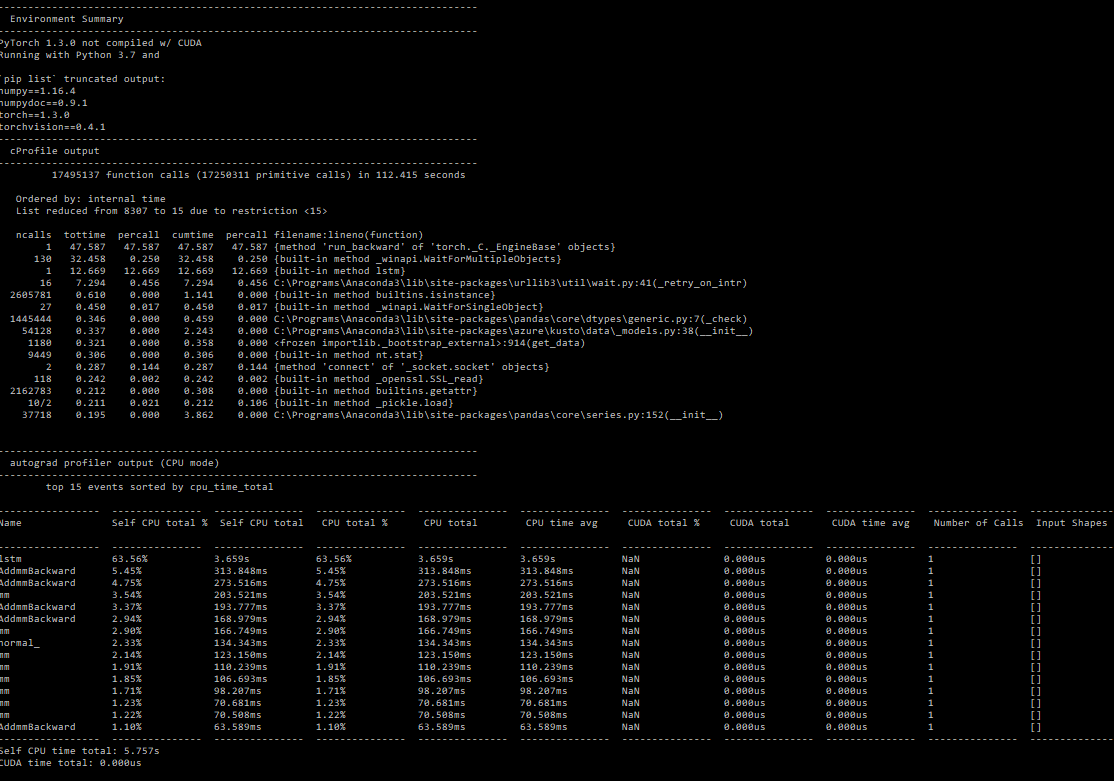
I see >5x slowdown on the .backward() call when using pack_padded_sequence (~80s instead of ~14s). Is this expected?
I am currently using a stack of 2 bidirectional lstms, what is the best practice for retrieving the final states when running on variable length inputs? I did this (not sure if correct / fastest approach):
concatenated = torch.cat(transformed, dim=2)
if True:
packed = pack_padded_sequence(concatenated, input_lengths, batch_first=True, enforce_sorted=False)
rnnout, _ = self.core_layers.lstm(packed) # out: tensor of shape (batch_size, seq_length, hidden_size*2)
unpacked = pad_packed_sequence(rnnout, batch_first=True)
final_per_seq = unpacked[0][torch.arange(unpacked[0].size(0)), unpacked[1]-1]
out = self.core_layers.fc(final_per_seq)
else: # I am using this to debug runtime issues of padding
concat_normed = self.core_layers.layernorm(concatenated)
rnnout, _ = self.core_layers.lstm(concat_normed) # out: tensor of shape (batch_size, seq_length, hidden_size*2)
out = self.core_layers.fc(rnnout[:, -1, :]) # this is probably the wrong way to index variable length sequences.