I am solving token classification problem. There is a huge class imbalance in data. Some of the classes have a million samples, others several hundred thousands. I saw many recommended to assign class weights to do 1/amount of samples per class. But this way gives me very small numbers. 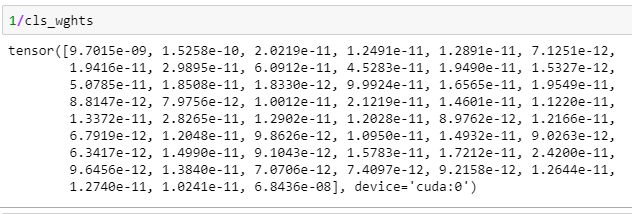
Does it make sense or I have to multiply this on smth like 10^n?
You could multiply the weights, if you are suspecting rounding errors or any other numerical issues.
The weights are used relatively, so you should be able to add a constant offset to the tensor.