Thankyou for this understanding. I now feel to take loss from shallow and middle layers only.
as you would have to choose the layers from where you want features
The famous paper Perceptual Losses for Real-Time Style Transfer
and Super-Resolution has the following diagram
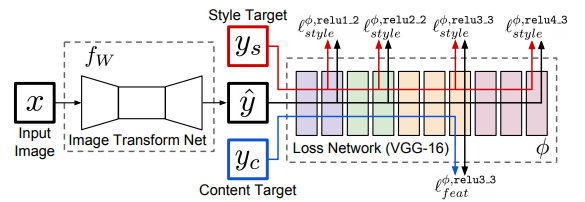
According to this for content loss relu3_3 is used but the in the description the paper says,
For all style transfer experiments we compute feature reconstruction loss at layer relu2_2
So can you please additionally help me which one will be more suitable for denoising task when perfectly aligned GT is available.
Thankyou
Mohit