Hi All
I’m LUA\Torch7 user.
Unfortunately Torch7 community seems dead, so Im here with my dumb question.
So main question is followings:
In multi-gpu data parallel, is every GPU calculate Batchnorm independently?
If so, can we “emulate” big batch simply by accumulating gradients for 8 batches and update network only every 8th iteration?
Will it be the same as using 8GPUs in terms of result?
Hi Ranahanocka,
Thanks for your reply.
I actually read that thread on github before asking that question, so My first question was asked just to confirm that I understand everything right.
Main question is second one, which could be reasked that way
What is profit of using multiGPU if we can emulate same(or even better) training process with single GPU?
Only training speed?
So it really depends on your application. Generally speaking, if your batchsize is large enough (but not too large), there’s not problem running batchnorm in the “data-parallel” way (i.e., the current pytorch batchnorm behavoir)
Assume your batches were too small (i.e., 1 sample per GPU), then the mean-var-stats (with the current batchnorm behavoir) during training would be useless. But if they were large enough, then the batchnorm stats (as given by data parallel) would be just fine.
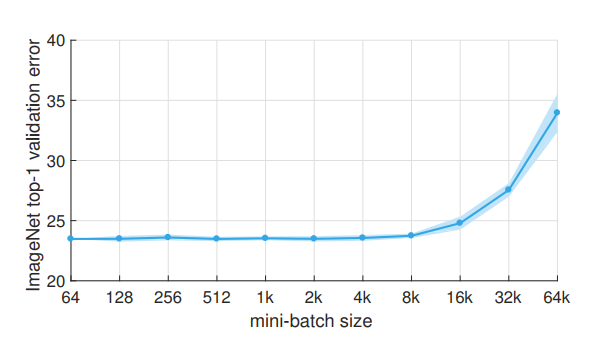
On the flip side, if there were hundreds of samples in each GPU and the mean-var-stats were calculated as you suggested, then there are some works, like Goyal et. al. show that this gives undesirable results:
Thanks again for your reply.
I read that paper, may be should read it more carefully. As I remmember they used unsynced BN and minibatch per GPU was always 32 through all their test.
So They didn’t exercises possible effects of different minibatch per BN.
Unfortunately I have to use minibatach of 16 per GPU.
Is this minibatch big enough?
According to paper unsynced minibatch increasing makes no sense, but what about synced one?
See section 2.3. But you are right. In the paper they wrote:
We also note that the BN statistics
should not be computed across all workers, not only for
the sake of reducing communication, but also for maintaining
the same underlying loss function being optimized.
But the point is, if BN was properly synced (which that repo above does) - it’s like effectively increasing the batch size. And, in general, I think there are concerns about having too large batch sizes. I don’t know if it’s conclusive or not, but yann lecunn said:
Training with large minibatches is bad for your health.
More importantly, it’s bad for your test error.
Friends dont let friends use minibatches larger than 32
when he posted this paper on twitter. In my experience, there is no hard-and-fast rules and really each network / data / problem is different. Unfortunately, what that means is that the best theory is just “try both and see what works better”.
AFAIK Lecunn postion was that we should use minibatch of 1.
In VGG-type networks I used minibatch of 4 or 8 and result were better and obtained faster.
The reason why it could be not a choice was GPU parrallel arch, when minibatch of 1 is not computionally optimal.
But that Yann’s position was before BN paper was issed. And BN limits our minibatch size, it couldn’t be 1 anymore.
So what is the minimal minibatch size which BN-stable?
How network behaves when minibatch became BN-unstable (when minibatch<BN_stable_size)?
Does anyone investigate this?
Which is doing semantic segmentation, and says the sync batch norm is important for this particular application (it uses another implementation which is based off a different repo)
Sweet Lady, thanks again for your reply
Can I ask you one more question?
AFAIK all those archs like ALexNet, VGG, ResNet, DenseNet and on… and on… and on… - All of them tested on ImageNet 1.3mln train data
from my expirience 1.3mln is quite small training dataset and could be easily overfitted.
Don’t you know is there any comparison of those Nets with bigger datasets?