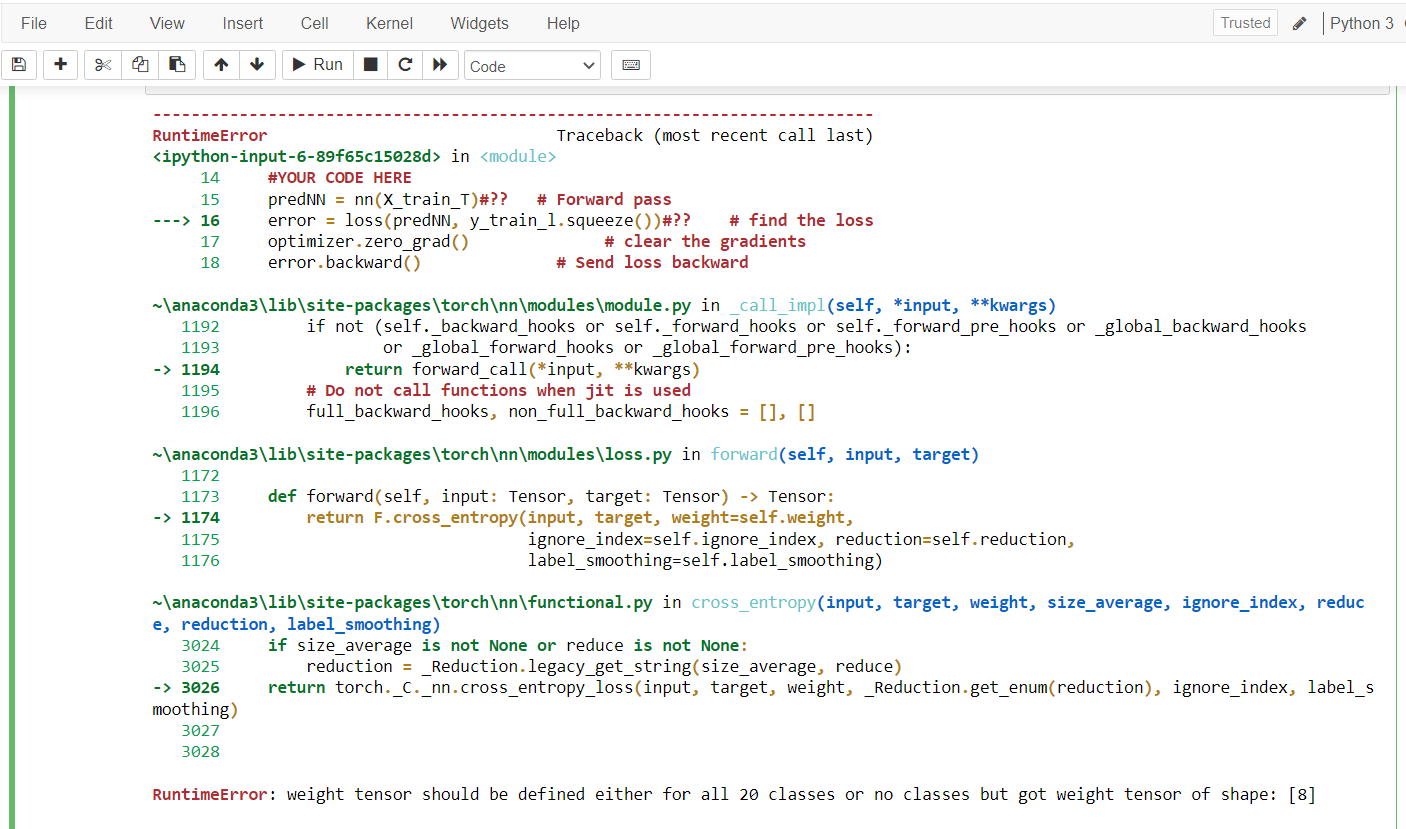
Getting error as :
RuntimeError Traceback (most recent call last)
<ipython-input-42-cafff645f983> in <module>()
13 print("targets[:, 0] size ==> ",len(targets[:, 0]))
14
---> 15 loss = criterion(outputs, targets[:, 0])
16 loss.backward()
17 optimizer.step()
/opt/anaconda/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
323 for hook in self._forward_pre_hooks.values():
324 hook(self, input)
--> 325 result = self.forward(*input, **kwargs)
326 for hook in self._forward_hooks.values():
327 hook_result = hook(self, input, result)
<ipython-input-1-992294f0aa44> in forward(self, outputs, targets)
11
12 def forward(self, outputs, targets):
---> 13 return self.loss(F.log_softmax(outputs), targets)
/opt/anaconda/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
323 for hook in self._forward_pre_hooks.values():
324 hook(self, input)
--> 325 result = self.forward(*input, **kwargs)
326 for hook in self._forward_hooks.values():
327 hook_result = hook(self, input, result)
/opt/anaconda/lib/python3.6/site-packages/torch/nn/modules/loss.py in forward(self, input, target)
145 _assert_no_grad(target)
146 return F.nll_loss(input, target, self.weight, self.size_average,
--> 147 self.ignore_index, self.reduce)
148
149
/opt/anaconda/lib/python3.6/site-packages/torch/nn/functional.py in nll_loss(input, target, weight, size_average, ignore_index, reduce)
1049 return torch._C._nn.nll_loss(input, target, weight, size_average, ignore_index, reduce)
1050 elif dim == 4:
-> 1051 return torch._C._nn.nll_loss2d(input, target, weight, size_average, ignore_index, reduce)
1052 else:
1053 raise ValueError('Expected 2 or 4 dimensions (got {})'.format(dim))
RuntimeError: weight tensor should be defined either for all or no classes at /opt/conda/conda-bld/pytorch_1513368888240/work/torch/lib/THNN/generic/SpatialClassNLLCriterion.c:60
Here is my code :
weight = torch.ones(22)
criterion = CrossEntropyLoss2d(weight)
for epoch in range(1, num_epochs+1):
epoch_loss = []
iteration=1
for step, (images, labels) in enumerate(trainLoader):
print("Iter:"+str(iteration))
iteration=iteration+1
inputs = Variable(images)
targets = Variable(labels)
outputs = model(inputs)
optimizer.zero_grad()
print("outputs size ==> ",len(outputs))
print("targets[:, 0] size ==> ",len(targets[:, 0]))
loss = criterion(outputs, targets[:, 0])
loss.backward()
optimizer.step()
epoch_loss.append(loss.data[0])
average = sum(epoch_loss) / len(epoch_loss)
print("loss: "+str(average)+" epoch: "+str(epoch)+", step: "+str(step))
Can you please help me here ?
Thanks in advance