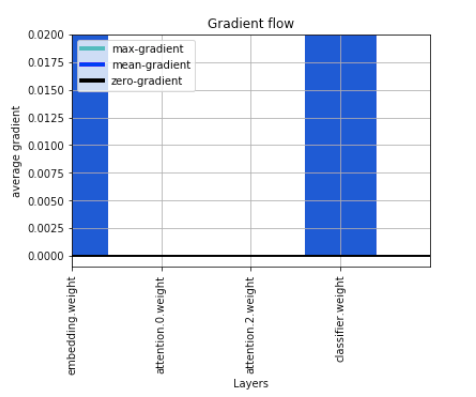
Hello I am new to pytorch and trying to implement a simple model with an attention layer. On inspection I am able to see that my model is not updating the weights for the attention layers in the model(code below). I have plotted the gradient flow and also used model.parameters() to check for weights before and after the .backward() and optimizer.step() calls and the weights remain the same.
My model
class ModelA(nn.Module):
def __init__(self):
super(ModelA,self).__init__()
self.L = 128
self.D = 64
self.K = 1
self.embedding=nn.Linear(24, self.L)
self.attention = nn.Sequential(
nn.Linear(self.L, self.D),
nn.Tanh(),
nn.Linear(self.D, self.K),
nn.InstanceNorm1d(19)
)
self.classifier= nn.Linear(self.L*self.K, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
embedding = self.embedding(x)
A = self.attention(embedding)
A = torch.transpose(A, 2, 1)
A = F.softmax(A, dim=1)
M = torch.bmm(A, embedding)
out = self.classifier(M.view(x.size(0),-1))
return self.sigmoid(out)
model Intialization and hyper-parameters
modelA=ModelA()
optimizer = torch.optim.SGD(modelA.parameters(), lr=0.0001)
loss_func = nn.MSELoss()
training code
for it in range(15):
modelA.train()
total=len(train_data_loader)*batch_size
train_loss = 0.
for minibatch in train_data_loader:
X, Y1, Y2 = minibatch
output = modelA(X)
optimizer1.zero_grad()
total_loss=loss_func(output,Y1.view(-1,1))
train_loss += total_loss.item()
# a = list(modelA.parameters())[2].clone()
total_loss.backward()
plot_grad_flow(list(modelA.named_parameters()))
optimizer.step()
# b = list(modelA.parameters())[2].clone()
# print(torch.equal(a.data, b.data))
train_loss /= total
print("EPOCH ",it)
print('Train : Loss: {:.4f}'.format(train_loss))
Gradient Flow