Hi,
I’m training a simple NN and I noticed a strange behavior during training and evaluation. I’m using DataLoaders with TensorDataset as follows
dataset_train = TensorDataset(X_train, Y_train)
dataset_test = TensorDataset(X_test, Y_test)
dataloader_train = DataLoader(dataset_train, batch_size=512, shuffle=True, drop_last=True,
pin_memory=False, num_workers=0)
dataloader_test = DataLoader(dataset_test, batch_size=512, shuffle=True,
pin_memory=True, num_workers=0)
Since the dataset is huge and since I want a fine grain evaluation of the network, instead of waiting an entire epoch to be completed, every X iterations (i.e. after X batches) it stops the training process, I evaluate the network and, finally, it continues with optimization.
This is how the loss function looks like testing every 50 and 250 iterations
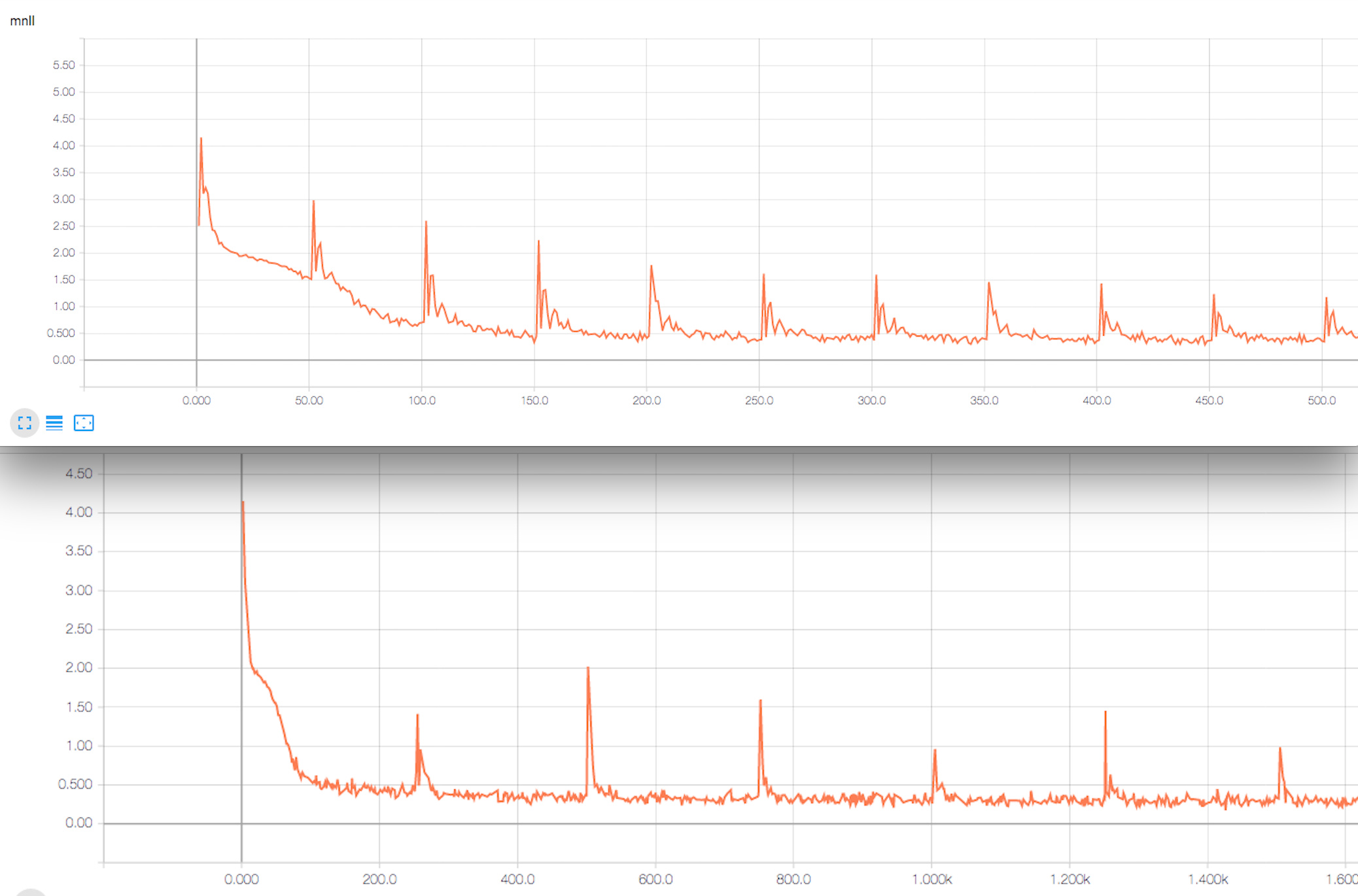
This is very weird, as it seems that the randomness of the dataloader is somehow broken when I restart the process. The same spike in the loss (maybe caused by the same batch?) is repeating exactly every X iteration (50 as well as 250).
Note that I’m not manually setting any seed and I’m not using CUDA/GPUs.
Do you have any idea of what might cause this behaviour?