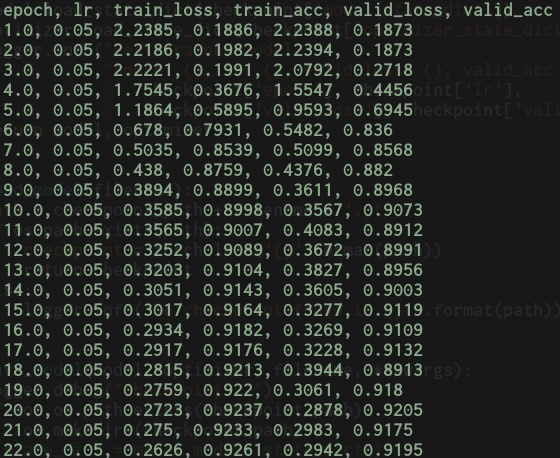
I’m currently facing a weird behaviour which I cannot explain. I’m training a vgg16 on svhn and training on 1 gpu with SGD and fixed hypeparams I get the following nice results:
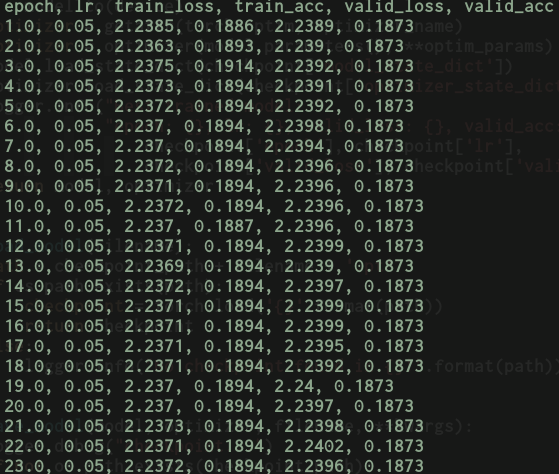
Now trying to train the same model with same optimizer and hyperparams as before but using DataParallel it exhibits the following behaviour where the learning process actually stagnates and it doesn’t learn anything.
Even more weird is the fact that if I swap vgg16 for resnet50 it starts learning again.
Anyone has any insights on this, or what it might be going on?
I would expect that if a model M trained on one device with fixed optimizer and hyperams exhibiting good learning behaviour to have the same behaviour when trained with DataParallel using same optimizer and hyperparams.
Could you post a minimal working example to reproduce these results? It could be, e.g. that you don’t pass the DataParallel’s parameters to the params argument of the optimizer
What do you mean by at the same position?
My understanding is that DataParallel takes data of batch size m and splits them as int(m/num_of_devices) sending to each device it’s own split and a copy of the model?