A new dataset of 60000 8x8 color images from 10 class, with 6000 images per class was create. The training set has 5400 images and the valid set has 600 images. The dataset was obtained by dividing into 8x8 blocks each of the images corresponding to the DIBCO 2017 and classified according to their characteristics by applying a transform in the frequency domain.
My code is the following:
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visualization.visdom import Visualizations
import numpy as np
from PIL import Image
import random
from io import BytesIO
# Initialize the visualization environment
vis = Visualizations()
#Var
train_loss_list = []
valid_loss_list = []
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(3 * 8 * 8, 385)
self.fc2 = nn.Linear(385, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.dropout(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(args, model, device, train_loader, optimizer, epoch):
# Before training the model, it is imperative to call model.train()
model.train()
global_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
data = data.view(args.batch_size, 3 * 8 * 8)
target = target.view(args.batch_size)
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
global_loss = (global_loss*(batch_idx) + loss.item())/(batch_idx+1)
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * args.batch_size, len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
return global_loss
def test(args, model, device, test_loader, epoch):
# You must call model.eval() before testing the model
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
data = data.view(args.test_batch_size, 3 * 8 * 8)
target = target.view(args.test_batch_size)
output = model(data)
# sum up batch loss
test_loss += F.nll_loss(output, target, reduction='sum').item()
# get the index of the max log-probability
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
acc = 100. * correct / len(test_loader.dataset)
print(
'\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset), acc))
return {'test_loss': test_loss, 'acc':acc}
def randomJpegCompression(image):
p = random.random()
outputIoStream = BytesIO()
if p > 0.9:
return image
elif p > 0.8:
image.save(outputIoStream, "JPEG", quality=75, optimice=True)
outputIoStream.seek(0)
elif p > 0.45:
image.save(outputIoStream, "JPEG", quality=50, optimice=True)
outputIoStream.seek(0)
else:
image.save(outputIoStream, "JPEG", quality=20, optimice=True)
outputIoStream.seek(0)
return Image.open(outputIoStream)
def main():
# Training settings
parser = argparse.ArgumentParser(description='FNN')
parser.add_argument(
'--batch-size', type=int, default=100, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument(
'--test-batch-size', type=int, default=100, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument(
'--epochs', type=int, default=600, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument(
'--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument(
'--momentum', type=float, default=0.9, metavar='M',
help='SGD momentum (default: 0.9)')
parser.add_argument(
'--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument(
'--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument(
'--log-interval', type=int, default=100, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument(
'--save-model', action='store_true', default=True,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
# Transforms
simple_transform = transforms.Compose(
[
transforms.Lambda(randomJpegCompression),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
)
# Dataset
train_dataset = datasets.ImageFolder('data/train/', simple_transform)
valid_dataset = datasets.ImageFolder('data/valid/', simple_transform)
# Data loader
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset, batch_size=args.batch_size, shuffle=True,
num_workers=2)
test_loader = torch.utils.data.DataLoader(
dataset=valid_dataset, batch_size=args.test_batch_size, shuffle=False, num_workers=2)
model = Net().to(device)
print(model)
optimizer = optim.SGD(
model.parameters(), lr=args.lr, momentum=args.momentum)
for epoch in range(1, args.epochs + 1):
global_loss_train = train(
args, model, device, train_loader, optimizer, epoch)
dic = test(args, model, device, test_loader, epoch)
# Visualization data
vis.plot_loss_train(global_loss_train, epoch)
vis.plot_loss_valid(dic['test_loss'], epoch)
vis.plot_acc(dic['acc'], epoch)
if (args.save_model):
torch.save(model.state_dict(), "fnnNew_600epoch_1xlayers385.pt")
if __name__ == '__main__':
main()
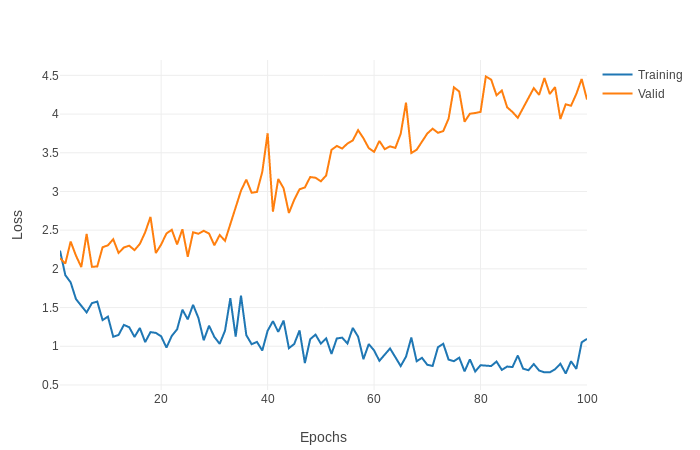
and these are the values of train and valid loss and accuracy that I get.
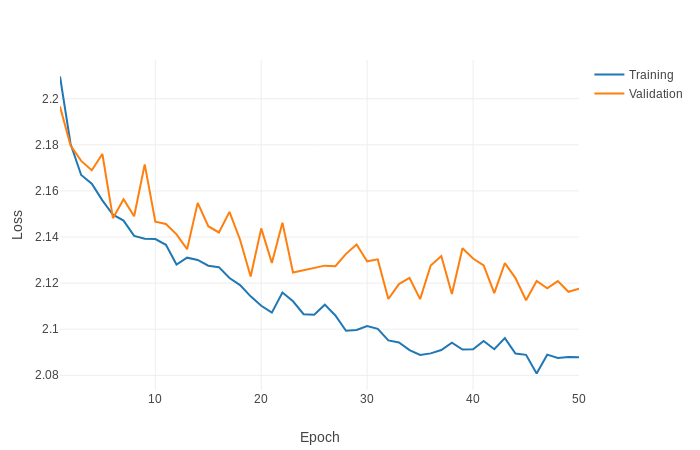
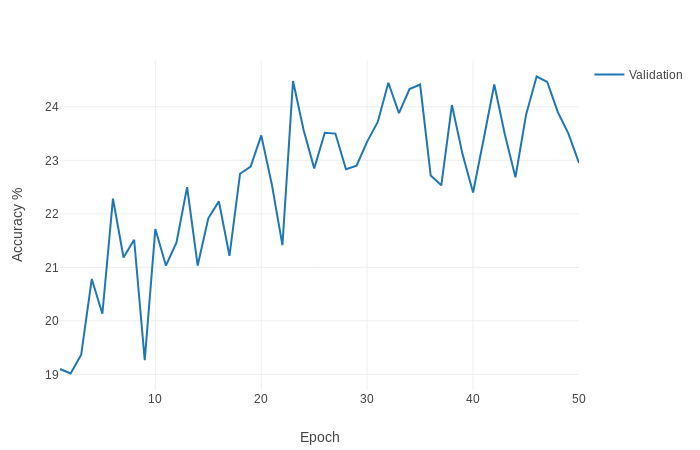
These values are not good. I see that the loss train is not low enough, or at least fast enough.
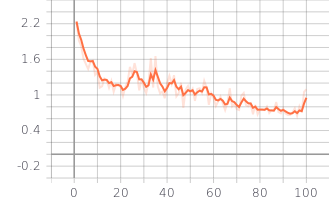
I have trained other models using a similar dataset and in the first periods both the loss train and the loss valid are less than 1.
Ej:
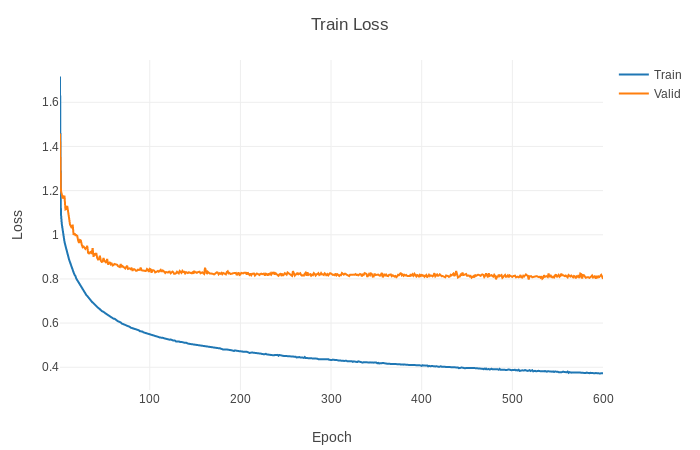
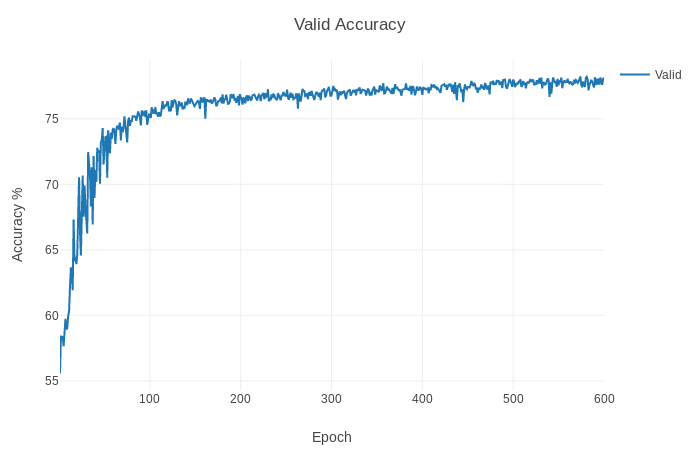
What can I do to get a better accuracy ??