Usually after a backpropagation you process the next batch so you don’t need the gradients of the previous batch anymore.
Besides debugging I don’t have any scenario for which I need to backprop twice through the same operation graph, I’m sure there are though.
The default is to drop the variables/gradient to save on memory.
All the source code of PyTorch is on github. From the name, I guess that self._execution_engine.run_backward is traversing the operation graph in reverse, calling backward if defined, or using the autograd if not.
Each node in the graph have several properties that are defined in the autograd folder of PyTorch
Actually, when we train a GAN, we usually should calculate the D_loss for discrimination net and G_loss for generator net And after calculating the gradient of D_loss,we need to retain variables for the calculation of G_loss,which is a typical example the “retain_variables=True” use.
In my (very limited) experience, you do not compute discriminator and generator gradients for the same forward step because the loss objectives have opposing signs.
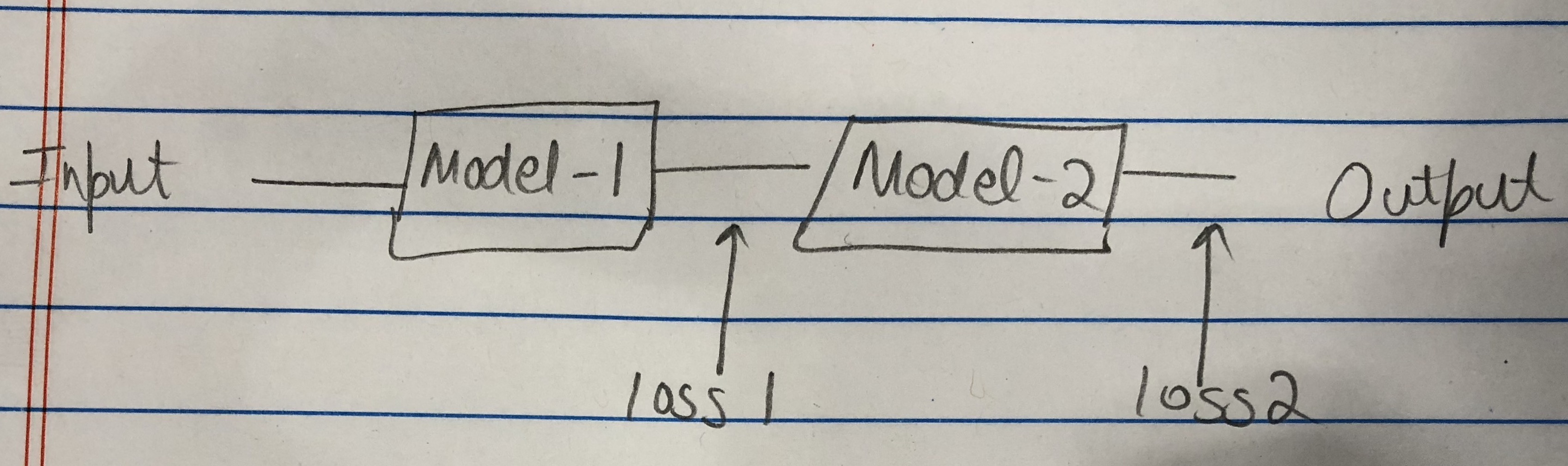
I think a concrete case where retain_graph=True is helpful is multi-task learning where you have different losses at different layers of the network. So in order to back-propagate the gradient of each loss w.r.t to the parameters of the network, you will need to set retain_graph=True, or you can only do backward for one of the many losses.
Here the input image is treated as variables, and a gradient is calculated to see which parts in the image will have most influence on the global classification decision.
This is useful when you trained a classifier without any localization and you still want to see some localization information.
I understand If I have two loss functions in different parts of the network, I’ll have use retain_graph. What if I add both the losses and do total_loss.backward() ?
Hi, @smth ,
I just started to use pytorch recently. And I also comfuse about above problem.
And I think above two ways may not same?
While use:
loss1.backward(retain_graph=True)
_ loss2.backward()_
_ opt.step()_
the layers between loss1 and loss2 will only calculate gradients from loss2.
and the layers before loss1 will calculate gradientes as sum of loss1+loss2
but if use:
total_loss = loss1 + loss2
_ total_loss.backward()_
_ opt.step()_
all layers will calculate gradient by using loss_value = loss1 + loss2
we need the variables or the part of computational graph of model-1, but we won’t update it’s parameters? e.g. in GAN. Are there any mistakes with my understanding?
As far as I think, loss = loss1 + loss2 will compute grads for all params, for params used in both l1 and l2, it sum the grads, then using backward() to get grad.
Meanwhile, loss1.backward() and loss2.backward() means seperately compute grads in loss1 and loss2, and get grads themselves.
The diff is that: When using optimizer to update step size using gd method, sum(loss).backward() using only 1 optimizer with sum of grads; and l1, l2 using 1 optimizer(or even 2 optimizer) to compute step-size based on the grads, for params which l1 and l2 owns in public, maybe the step-size is depended on l2 loss(which computes later).
There is no diff between them when it comes to updating weights. When you call loss1.backward(retain_graph=True) and then loss2.backward() the gradients are added just like calling total_loss.backward().
If you want to have 2 optimizers or compute step size based on gradients then yes maybe it will lead to different updates.
This question has generated more traction than I thought. It seems to bother many users why method 1 and method 2 are same. So here is a small snippet showing the gradient obtained from method1 and method 2 is same.
import torch
# define model 1 and model 2
class net1(torch.nn.Module):
def __init__(self):
super(net1, self).__init__()
self.fc = torch.nn.Linear(2,2)
def forward(self, x):
return self.fc(x)
class net2(torch.nn.Module):
def __init__(self):
super(net2, self).__init__()
self.fc = torch.nn.Linear(2,1)
def forward(self, x):
return self.fc(x)
# define loss 1 and loss 2
loss1 = torch.nn.MSELoss()
loss2 = torch.nn.L1Loss()
# define random input (x) and output (y)
x = torch.randn(1,2)
y1 = torch.randn(1,2)
y2 = torch.randn(1,1)
model1 = net1()
model2 = net2()
# method 1
y1_hat = model1(x)
loss1(y1_hat, y1).backward(retain_graph=True)
y2_hat = model2(y1_hat)
loss2(y2_hat, y2).backward()
# we compute gradient norm of weights on model1
print("gradient norm method1: {0}".format(torch.norm(model1.fc.weight.grad)))
# method 2 (zero previous gradient to run method 2)
model1.zero_grad()
model2.zero_grad()
y1_hat = model1(x)
y2_hat = model2(y1_hat)
total_loss = loss1(y1_hat, y1) + loss2(y2_hat, y2)
total_loss.backward()
# we compute gradient norm of weights on model1
print("gradient norm method2: {0}".format(torch.norm(model1.fc.weight.grad)))