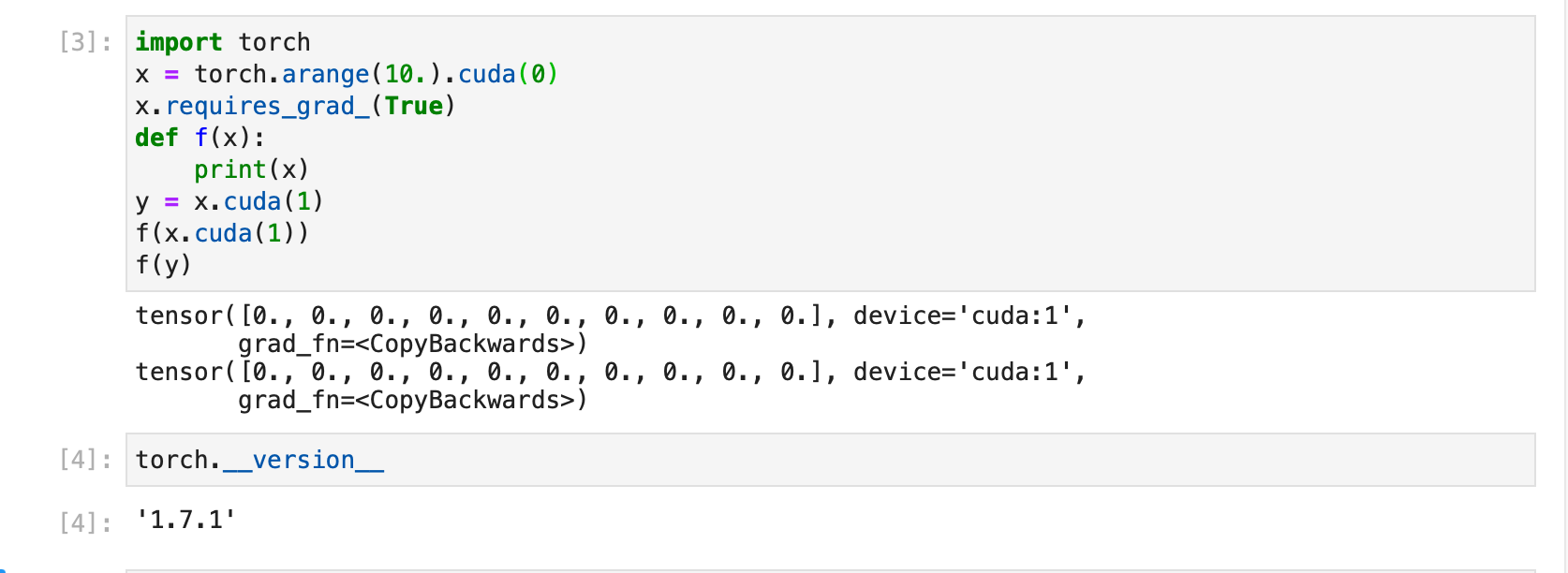
Hi,
Can anyone explain it to me please?
thx!
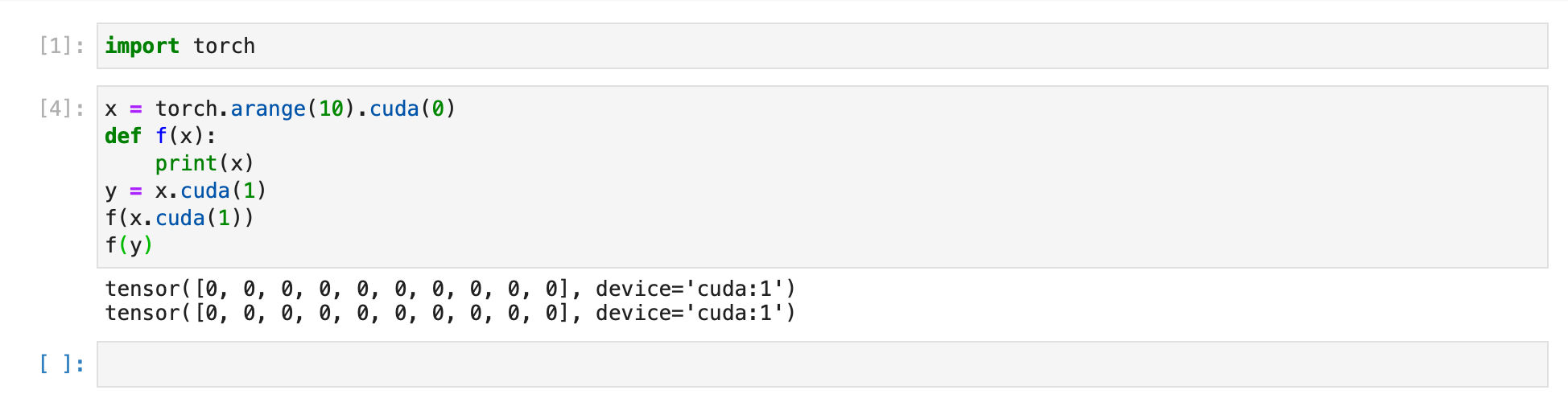
But it turns out that in another situation, this tensor transfer between different gpu is doable:
In the following code, I put the encoder and decoder of a auto encoder in different gpu ,and in forward function I manually change the data device:
f = True
class LitAutoEncoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 64),
nn.ReLU(),
nn.Linear(64, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 28*28)
)
self.encoder = self.encoder.cuda(0)
self.decoder = self.decoder.cuda(1)
def forward(self, batch, batch_idx=None):
global f
x, y = batch
x = x.view(x.size(0), -1)
x = x.cuda(0)
z = self.encoder(x)
if f:
print(z.cuda(1))
f = False
x_hat = self.decoder(z.cuda(1))
loss = F.mse_loss(x_hat.cuda(0), x)
return loss
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
train_loader = DataLoader(dataset,num_workers=4,batch_size=12)
autoencoder = LitAutoEncoder()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=1e-3)
losses = []
print_cnt = 0
for batch in train_loader:
optimizer.zero_grad()
loss = autoencoder(batch)
loss.backward()
losses.append(loss.item())
optimizer.step()
and here is the output:
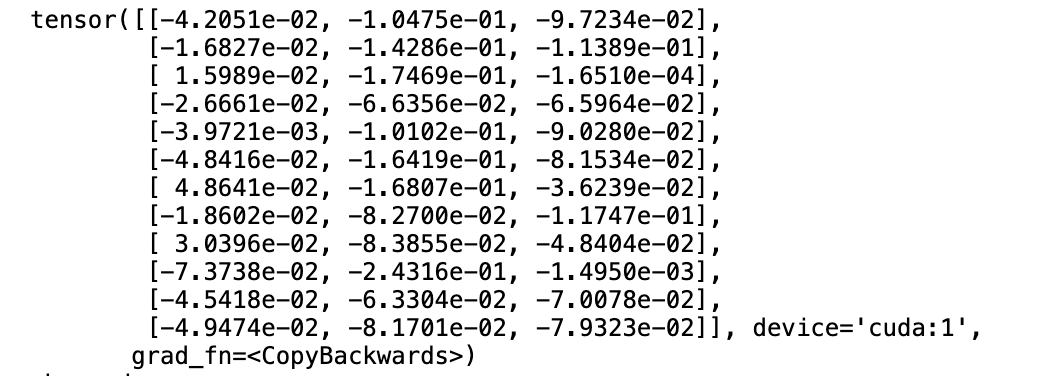
I seemed to find some clue, but I am not so sure.
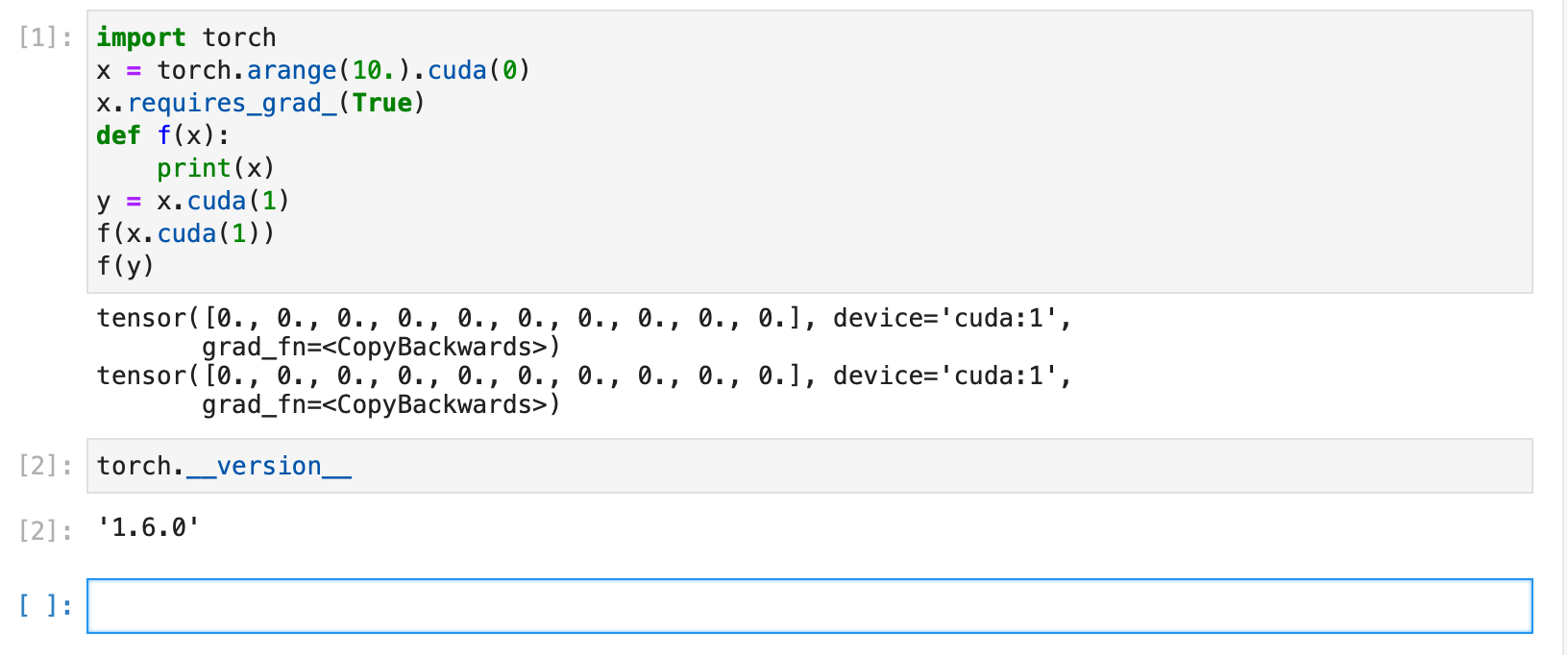

The result is different in different version
emm…