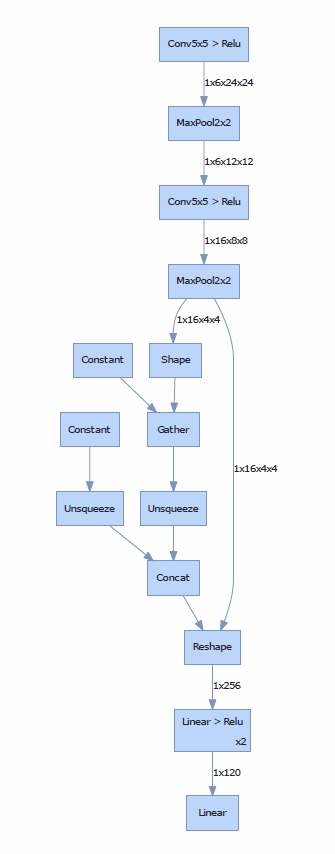
Two nn models are defined below. for simplicity, let’s call them LeNet1 and LeNet2. From the code snippets, we can see that their forward functions are completely same, the only difference is the order of the layers in class initialization method. LeNet2 simply gets out of the normal order.
Since the forward functions are identical, I’d expect those two networks would generate the same output if we feed the same input to them. However, the experimentation result does not support that.
Any thoughts on this? Much appreciated.
class LeNet1(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5) ##output: (1,6,24,24)
self.conv2 = nn.Conv2d(6,16, 5)
self.fc1 = nn.Linear(16*4*4,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x = F.max_pool2d(F.relu(self.conv2(x)),2)
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class LeNet2(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(16*4*4,120)
self.conv2 = nn.Conv2d(6,16, 5)
self.fc3 = nn.Linear(84,10)
self.conv1 = nn.Conv2d(3, 6, 5)
self.fc2 = nn.Linear(120,84)
def forward(self,x):
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x = F.max_pool2d(F.relu(self.conv2(x)),2)
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def seed_everything(seed=123456):
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
seed_everything()
inp = torch.randn(1,3,28,28)
test1 = LeNet1()
test2 = LeNet2()
test1(inp),test2(inp)
Outputs:
(tensor([[ 0.1197, -0.0631, 0.0227, -0.0620, 0.0760, 0.0856, 0.0775, -0.0713,
-0.0762, 0.0417]], grad_fn=<AddmmBackward>),
tensor([[-0.0264, 0.0233, 0.0904, -0.0755, 0.0279, -0.0459, 0.0838, -0.0263,
-0.0738, 0.0075]], grad_fn=<AddmmBackward>))
I was also trying to print out their network architectures to see if there is any minor difference that I ignored. However, the result shows they have exactly same network graph. see below for reference.