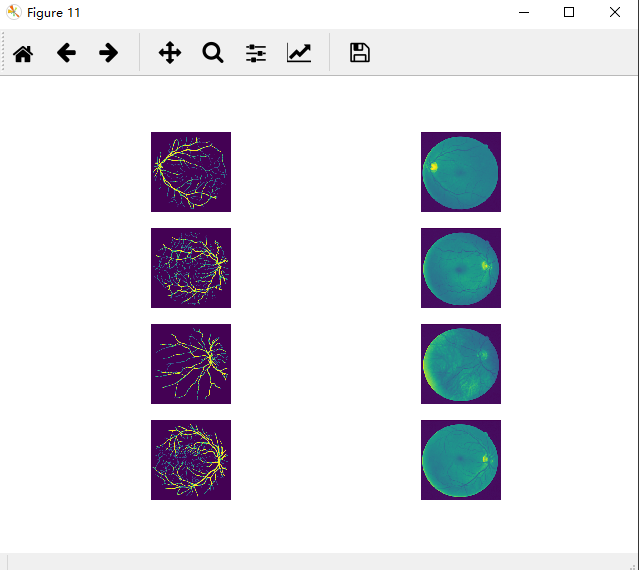
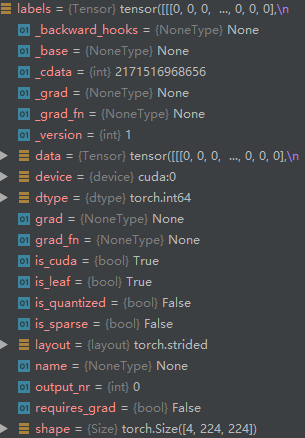
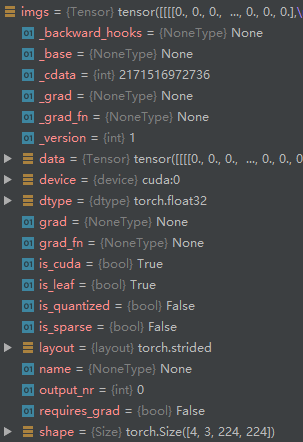
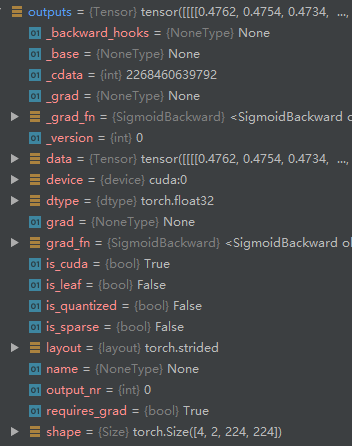
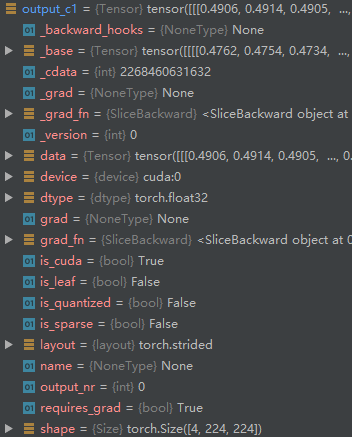
this is my train.py I use crosssentropy loss for my network , outputs size is [4,2,224,224] where 4 means batchsize, 2 means channels, 224 means h and w .output_c1 size is [4,224,224] ,labels size is [4,224,224] too.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from model import U_net
import visdom
from dataset import driveDateset
from torch import optim
from Dice_loss import DiceLoss
from Dice_loss import MulticlassDiceLoss
import matplotlib.pylab as plt
import numpy as np
import time
if __name__ == '__main__':
DATA_DIRECTORY = "F:\\experiment_code\\U-net\\DRIVE\\training"
DATA_LIST_PATH = "F:\\experiment_code\\U-net\DRIVE\\training\\images_id.txt"
Batch_size = 4
epochs = 100
dst = driveDateset(DATA_DIRECTORY, DATA_LIST_PATH)
# Initialize model
device = torch.device("cuda")
model = U_net()
model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
criteon = nn.CrossEntropyLoss() #reduce=False
best_acc, best_epoch =0, 0
global_step = 0
start_time = time.time()
viz = visdom.Visdom()
for epoch in range(epochs):
running_corrects = 0
since_epoch = time.time()
trainloader = torch.utils.data.DataLoader(dst, batch_size=Batch_size) #,shuffle =True
for step, data in enumerate(trainloader):
imgs, labels, _, _ = data
imgs, labels = imgs.to(device), labels.to(device)
labels = labels.long()
model.train()
outputs = model(imgs) # output B * C * H *W
output_c1 = outputs[:,0,:,:] # C are 2 channels ,I choose the second channel
Rounding_output_c1 = torch.round(output_c1)
Rounding_output_c11 = torch.stack([(Rounding_output_c1 == i).float() for i in range(256)]) #[4,224,224]->[256,4,224,224] 256 is the number of classes, means pixel from 0-255
Rounding_output_c11 = Rounding_output_c11.permute(1,0,2,3) #[256,4,224,224]->[4,256,224,224]
loss = criteon(Rounding_output_c11,labels)
loss.requires_grad = True
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()],[global_step], win='loss', update='append',opts=dict(title='train_loss'))
labels_float = labels.float()
running_corrects = torch.sum(Rounding_output_c1 == labels_float).float()
labels_size = labels.size(1) * labels.size(2) * 4
training_acc = running_corrects / labels_size
time_elapsed_epoch = time.time() - since_epoch
print('epoch :', epoch, '\t', 'loss:', loss.item(),'\t','training_acc',training_acc,'\t','{:.0f}m {:.0f}s'.format(time_elapsed_epoch // 60, time_elapsed_epoch % 60))
global_step += 1
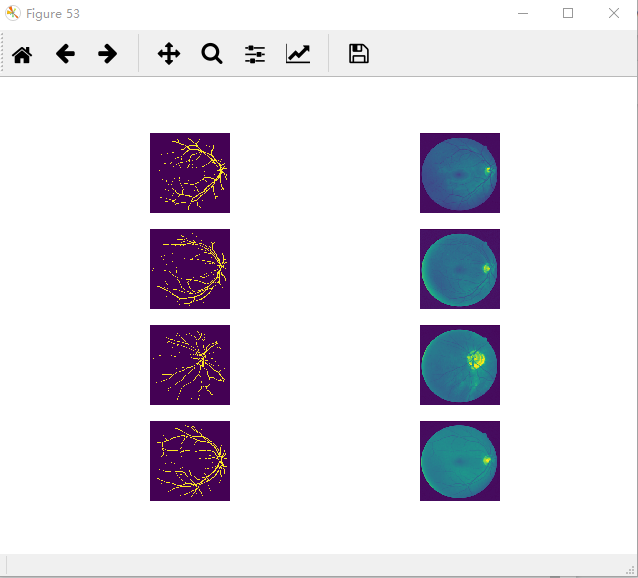
I test Data incoming has no problem ,every training data has Traversed. training data and label like this
but when I train my network ,output picture like this ,
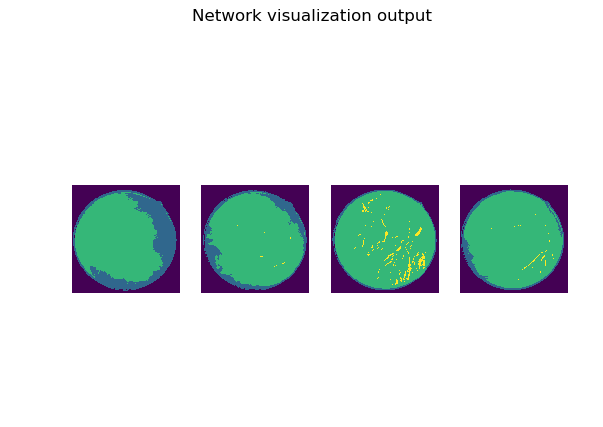
and some result like this :
epoch : 0 loss: 5.2415571212768555 training_acc tensor(0.3103, device='cuda:0') 0m 2s
epoch : 0 loss: 5.228370666503906 training_acc tensor(0.3235, device='cuda:0') 0m 2s
epoch : 0 loss: 5.224219799041748 training_acc tensor(0.3276, device='cuda:0') 0m 2s
epoch : 0 loss: 5.222436428070068 training_acc tensor(0.3294, device='cuda:0') 0m 2s
epoch : 0 loss: 5.2202887535095215 training_acc tensor(0.3316, device='cuda:0') 0m 2s
epoch : 1 loss: 5.2415571212768555 training_acc tensor(0.3103, device='cuda:0') 0m 0s
epoch : 1 loss: 5.22836971282959 training_acc tensor(0.3235, device='cuda:0') 0m 0s
epoch : 1 loss: 5.224219799041748 training_acc tensor(0.3276, device='cuda:0') 0m 0s
epoch : 1 loss: 5.222436428070068 training_acc tensor(0.3294, device='cuda:0') 0m 1s
epoch : 1 loss: 5.2202887535095215 training_acc tensor(0.3316, device='cuda:0') 0m 1s
epoch : 2 loss: 5.2415571212768555 training_acc tensor(0.3103, device='cuda:0') 0m 0s
epoch : 2 loss: 5.22836971282959 training_acc tensor(0.3235, device='cuda:0') 0m 0s
epoch : 2 loss: 5.224219799041748 training_acc tensor(0.3276, device='cuda:0') 0m 0s
epoch : 2 loss: 5.222436428070068 training_acc tensor(0.3294, device='cuda:0') 0m 1s
epoch : 2 loss: 5.2202887535095215 training_acc tensor(0.3316, device='cuda:0') 0m 1s
epoch : 3 loss: 5.2415571212768555 training_acc tensor(0.3103, device='cuda:0') 0m 0s
epoch : 3 loss: 5.22836971282959 training_acc tensor(0.3235, device='cuda:0') 0m 0s
epoch : 3 loss: 5.224219799041748 training_acc tensor(0.3276, device='cuda:0') 0m 0s
epoch : 3 loss: 5.222436428070068 training_acc tensor(0.3294, device='cuda:0') 0m 1s
epoch : 3 loss: 5.2202887535095215 training_acc tensor(0.3316, device='cuda:0') 0m 1s
I don’t konw how to solve this problem