import numpy as np
from collections import Counter
from sklearn import datasets
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
import torch
import torch.utils.data as Data
import pandas as pd
import torch.nn as nn
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import train_test_split
import torch.utils.data as utils
import torch.utils.data as td
dataframe= pd.read_csv('iris dataset classification/car.csv')
dataframe.columns = ['buying','maint','doors','persons','lug_boot','safety','classes']
dataframe.buying.replace(('vhigh','high','med','low'),(1,2,3,4), inplace=True)
dataframe.maint.replace(('vhigh','high','med','low'),(1,2,3,4), inplace=True)
dataframe.doors.replace(('2','3','4','5more'),(1,2,3,4), inplace=True)
dataframe.persons.replace(('2','4','more'),(1,2,3), inplace=True)
dataframe.lug_boot.replace(('small','med','big'),(1,2,3), inplace=True)
dataframe.safety.replace(('low','med','high'),(1,2,3), inplace=True)
dataframe.classes.replace(('unacc','acc','good','vgood'),(0,1,2,3), inplace=True)
array = dataframe.values
x = array[:,:6]
y = array[:,6]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.20, random_state=0)
train_x = torch.Tensor(x_train).float()
train_y = torch.Tensor(y_train).long()
train_ds = utils.TensorDataset(train_x,train_y)
train_loader = td.DataLoader(train_ds, batch_size=10,shuffle=True, num_workers=1)
test_x = torch.Tensor(x_test).float()
test_y = torch.Tensor(y_test).long()
test_ds = utils.TensorDataset(test_x,test_y)
test_loader = td.DataLoader(test_ds, batch_size=10, shuffle=True, num_workers=1)
class IrisNet(nn.Module):
def __init__(self):
super(IrisNet, self).__init__()
self.fc1 = nn.Linear(6, 50)
self.fc3 = nn.Linear(50, 4)
def forward(self, x):
x = F.relu(self.fc1(x))
x = torch.softmax(self.fc3(x),dim=1)
return x
model = IrisNet()
def train(model, data_loader, optimizer):
model.train()
train_loss = 0
for batch, tensor in enumerate(data_loader):
data, target = tensor
optimizer.zero_grad()
out = model(data)
loss = loss_criteria(out, target)
train_loss += loss.item()
loss.backward()
optimizer.step()
avg_loss = train_loss / len(data_loader.dataset)
return avg_loss
def test(model, data_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for batch, tensor in enumerate(data_loader):
data, target = tensor
out = model(data)
test_loss += loss_criteria(out, target).item()
_, predicted = torch.max(out.data, 1)
correct += torch.sum(target==predicted).item()
avg_accuracy = correct / len(data_loader.dataset)
avg_loss = test_loss / len(data_loader.dataset)
return avg_loss, avg_accuracy
loss_criteria = nn.CrossEntropyLoss()
learning_rate = 0.01
optimizer= torch.optim.Adam(model.parameters(), lr=learning_rate, betas=(0.9, 0.99))
epoch_nums = []
training_loss = []
validation_loss = []
epochs = 600
for epoch in range(1, epochs + 1):
train_loss = train(model, train_loader, optimizer)
test_loss, accuracy = test(model, test_loader)
epoch_nums.append(epoch)
training_loss.append(train_loss)
validation_loss.append(test_loss)
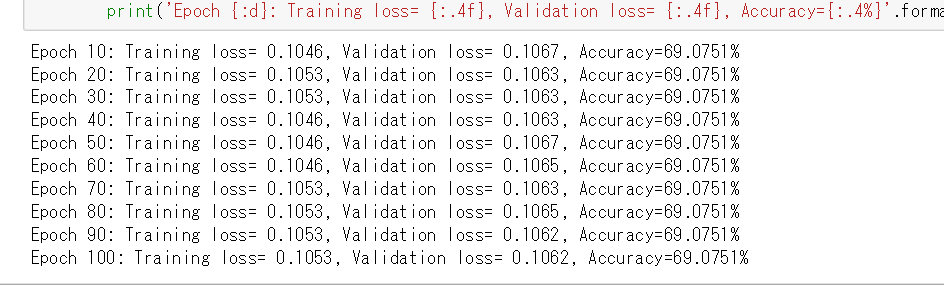
if (epoch) % 10 == 0:
print('Epoch {:d}: Training loss= {:.4f}, Validation loss= {:.4f}, Accuracy={:.4%}'.format(epoch, train_loss, test_loss, accuracy))