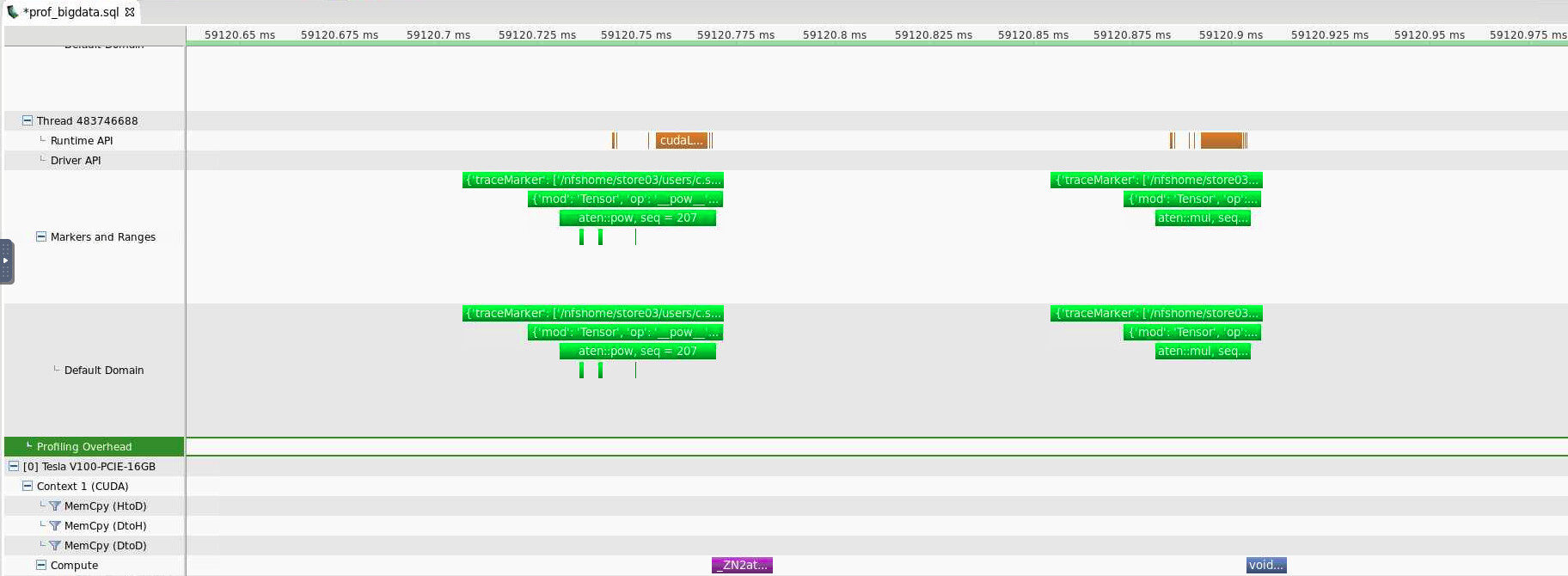
I am profiling my pytorch module with nvvp; it seems to have very low gpu usage.
Looking at one section of the profiler output - in this case this is from a line of code which raises each element of a pytorch cuda tensor to a constant power e.g. tensor**x (with tensor.requires_grad=True) - I see that compared to the CUDA compute time, large time periods are taken by
(i) the CPU - is this really expected to be longer than the CUDA time for a tensor of 500,000 elements?
and (ii) by a mysterious latency between the end of the CUDA operation and the start of the next CPU op. Given execution should be asynchronous, why is this here?
Note there is no memcpy going on so I’m assuming my tensor is on the gpu as it should be.