I use this script for finetuning different pretrained models in PyTorch on a custom dataset. My custom dataset has 200 categories, average 60 images per category, so totally 12000 images. And I split this dataset into 6000 training images and 6000 test images.
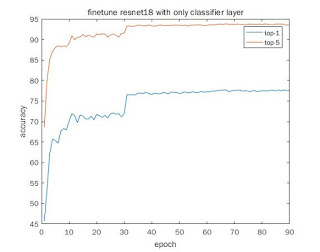
[1] finetuing only the last classifier layer without data augmentation
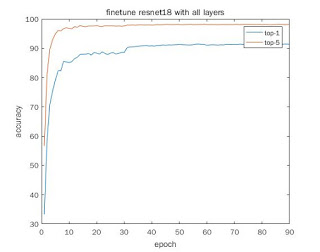
[2] finetuing with all the layers without data augmentation
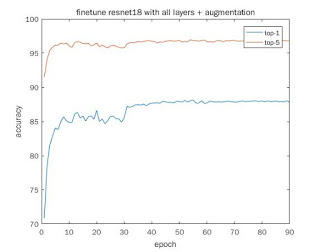
Because this dataset has imbalance in class, e.g. some classes have 45 images each, and some classes have 30 images each. So I use data augmentation to augment the training set up to 256 images per category. The test set is not change. Specifically, I use these strategies for data augmentation:
- random flip
- random crop
- random blur
- random sharpen
- random contrast enhancement
- random affine transformation
[3] finetuning with all layers and data augmentation
- comparision
| | top-1 | top-5 |
|-----|-------|-------|
| [1] | 77.5 | 93.6 |
| [2] | 91.3 | 98.1 |
| [3] | 87.8 | 96.8 |
From the above table, you can see:
- finetuing with all layers can get higher top-1 accuracy than finetuing with only the classifier (91.3 vs 77.5). This is desired.
- However, finetuing without data augmentation can still get higher top-1 accuray than with data augmentation (91.3 vs 87.8). This is for resnet18. I also tried resnet34, and get similar result. Originally, I think use data augmentation can get higher accuracy, but it didn’t.
So my question:
- Why data augmentation leads to decreased accuracy when finetuning?
- What data augmentation used in PyTorch ImageNet training? From the training code, I just see only random crop and random flip are used.