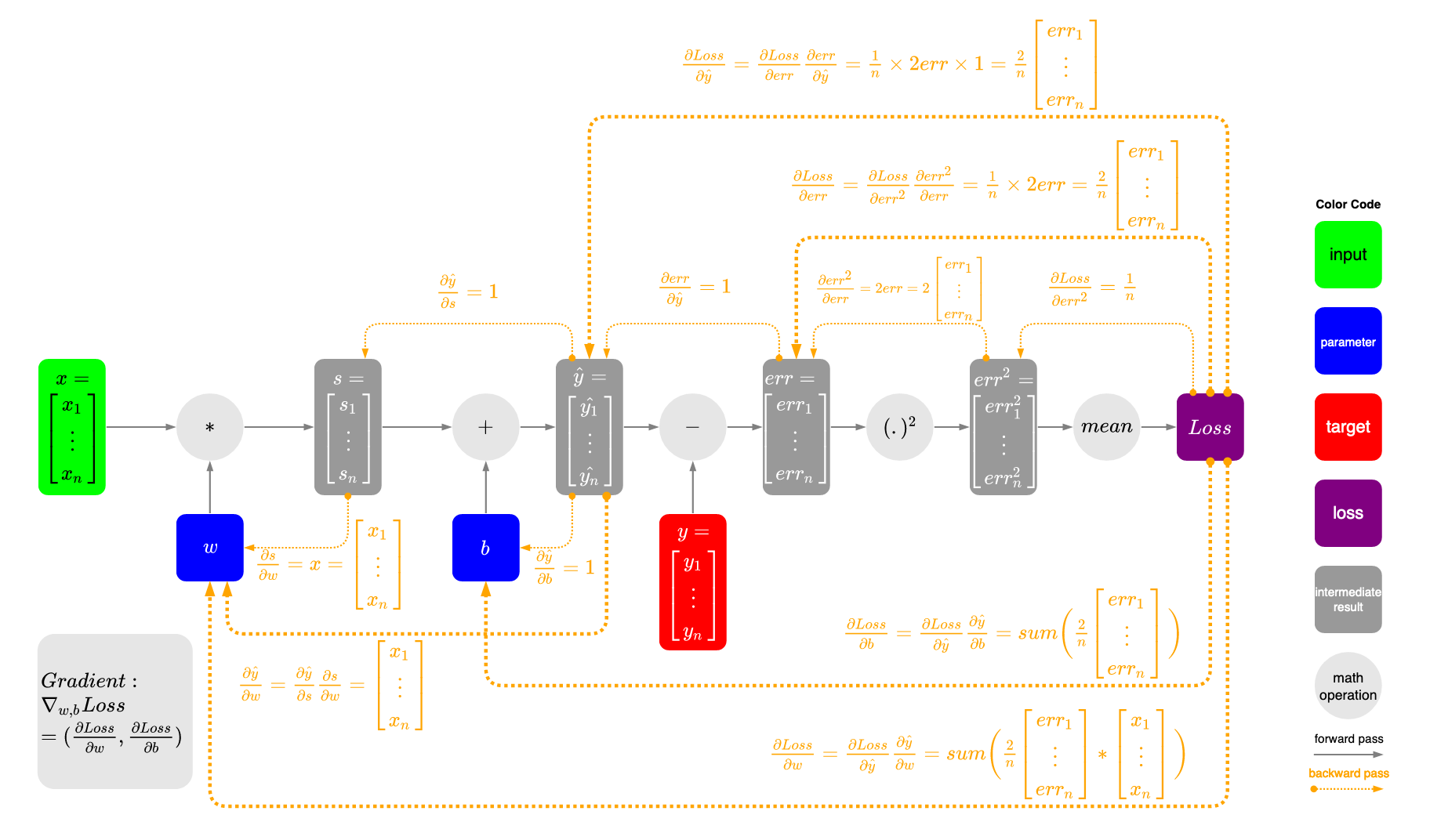
I’m reading “Deep Learning with PyTorch” by Eli Stevens, Luca Antiga, and Thomas Viehmann. As shown on page 116, the gradients for w and b are calculated as dloss_dw.sum() and dloss_db.sum().
Although the authors offered explanations, can you help to understand:
- Why the element-wise multiplication between
dloss_dtpanddmodel_dw, and that betweendloss_dtpanddmodel_db? - Why the summation for
dloss_dwanddloss_db, when returning the gradient vector?
I created a diagram as shown below to help myself to understand the vector calculations under the hood. However, I’m still not sure why the summation is applied in the last step. (x is t_u, y_hat is t_p, y is t_c in the book)
Thanks.
Excerpt from page 116 in “Deep Learning with PyTorch”:

My diagram on gradient calculation: