I coded in a DQN (without any target network). For some reason, the algorithm fails to learn any meaningful policy. Here’s my code. I will highly appreciate any and all suggestions and criticisms ![]()
#!/usr/bin/env python
# coding: utf-8
# In[66]:
# Here we import all libraries
import numpy as np
import gym
import matplotlib.pyplot as plt
import os
import torch
import random
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from collections import deque
import sys
env = gym.make("CartPole-v0")
# In[67]:
#Hyperparameters
episodes = 20000
eps = 1.0
learning_rate = 0.001
tot_rewards = []
tot_loss = []
decay_val = 0.0001
mem_size = 5000
batch_size = 100
gamma = 0.99
max_steps = 200
# In[68]:
class NeuralNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(NeuralNetwork, self).__init__()
self.state_size = state_size
self.action_size = action_size
self.linear_relu_stack = nn.Sequential(
nn.Linear(state_size, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, action_size)
)
def forward(self, x):
x = self.linear_relu_stack(x)
return x
# In[69]:
model = NeuralNetwork(env.observation_space.shape[0], env.action_space.n)
opt = torch.optim.Adam(params=model.parameters(), lr=learning_rate)
replay_buffer = deque(maxlen=mem_size)
# In[70]:
#Testing code
# state = torch.tensor(env.reset(), dtype=torch.float32)
# print("state = ", state)
# out = model(state)
# print("out = ", out)
# In[71]:
def compute_td_loss(batch_size):
state, next_state, reward, done, action = zip(*random.sample(replay_buffer, batch_size))
state = torch.stack(list(state), dim=0).reshape(batch_size, -1)
next_state = torch.from_numpy(np.array(next_state).reshape(batch_size, -1)).type(torch.float32)
reward = torch.from_numpy(np.array(reward))
done = torch.from_numpy(np.array(done)).long()
action = torch.from_numpy(np.array(action)).type(torch.int64)
q_values = model(state)
next_q_values = model(next_state)
q_vals = q_values.gather(dim=-1, index=action.reshape(-1,1)).reshape(-1, 1)
max_next_q_values = torch.max(next_q_values,-1)[0].detach()
loss = ((reward + gamma*max_next_q_values*(1-done) - q_vals)**2).mean()
opt.zero_grad()
loss.backward()
opt.step()
return loss
# In[72]:
for i in range(episodes):
print("Episode = ", i, " Epsilon = ", eps)
state = torch.tensor(env.reset(), dtype=torch.float32)
done = False
steps = 0
eps_rew = 0
eps_loss = 0
while not done and steps<max_steps:
if np.random.uniform(0,1)<eps:
action = env.action_space.sample()
else:
action = np.argmax(model(state).detach().numpy())
next_state, reward, done, info = env.step(action)
replay_buffer.append((state, next_state, reward, done, action))
if len(replay_buffer)>batch_size:
loss = compute_td_loss(batch_size)
eps = eps/(1 + decay_val)
eps_rew += reward
eps_loss += loss.detach().numpy()
if done:
tot_rewards.append(eps_rew)
break
state = next_state
state = torch.tensor(state, dtype=torch.float32)
steps += 1
tot_rewards.append(eps_rew)
tot_loss.append(eps_loss)
if(i%100)==0:
plt.scatter(np.arange(len(tot_rewards)), tot_rewards)
# plt.scatter(np.arange(len(tot_loss)), tot_loss)
plt.show()
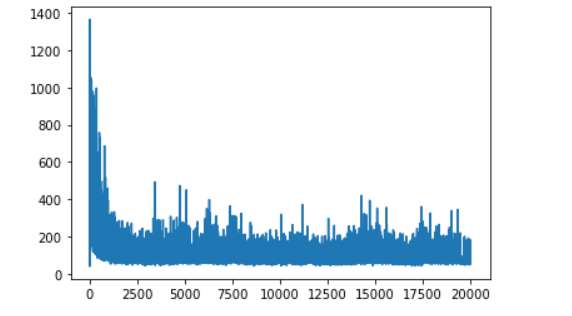
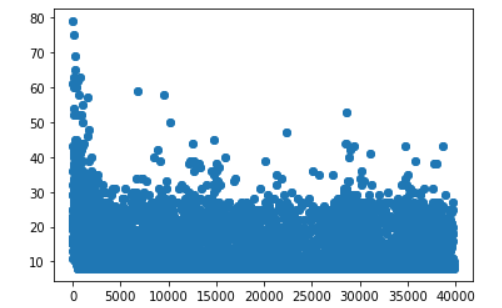
Here is my reward per step -
Here is my loss -