Hi,
Using this as loss criterion:
class TripletLoss(torch.nn.Module):
def __init__(self, margin):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, anchor, positive, negative):
distance_positive = (anchor - positive).pow(2).sum(1)
distance_negative = (anchor - negative).pow(2).sum(1)
losses = torch.nn.functional.relu(distance_positive - distance_negative + self.margin)
return losses.mean()
And this as a network:
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = torch.nn.Conv2d(1, 16, 5)
self.pool1 = torch.nn.MaxPool2d(2)
self.conv2 = torch.nn.Conv2d(16, 64, 3)
self.pool2 = torch.nn.MaxPool2d(2)
self.conv3 = torch.nn.Conv2d(64, 128, 3)
self.pool3 = torch.nn.MaxPool2d(2)
self.linear1 = torch.nn.Linear(1152, 512)
self.linear2 = torch.nn.Linear(512, 64)
def forward(self, x):
x = torch.nn.functional.relu(self.conv1(x))
x = self.pool1(x)
x = torch.nn.functional.relu(self.conv2(x))
x = self.pool2(x)
x = torch.nn.functional.relu(self.conv3(x))
x = self.pool3(x)
x = x.view(x.shape[0], -1)
x = torch.nn.functional.relu(self.linear1(x))
x = torch.nn.functional.relu(self.linear2(x))
return x
I train the network with random data. I also print the value of the loss returned by the criterion.
if __name__ == '__main__':
model = Net()
criterion = TripletLoss(0.5)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
model.train()
for x in range(10000):
optimizer.zero_grad()
x = torch.tensor(np.random.normal(size=[1, 1, 40, 40])).float()
y = torch.tensor(np.random.normal(size=[1, 1, 40, 40])).float()
z = torch.tensor(np.random.normal(size=[1, 1, 40, 40])).float()
anchor = model(x)
positive = model(y)
negative = model(z)
loss = criterion(anchor, positive, negative)
print(loss)
loss.backward()
optimizer.step()
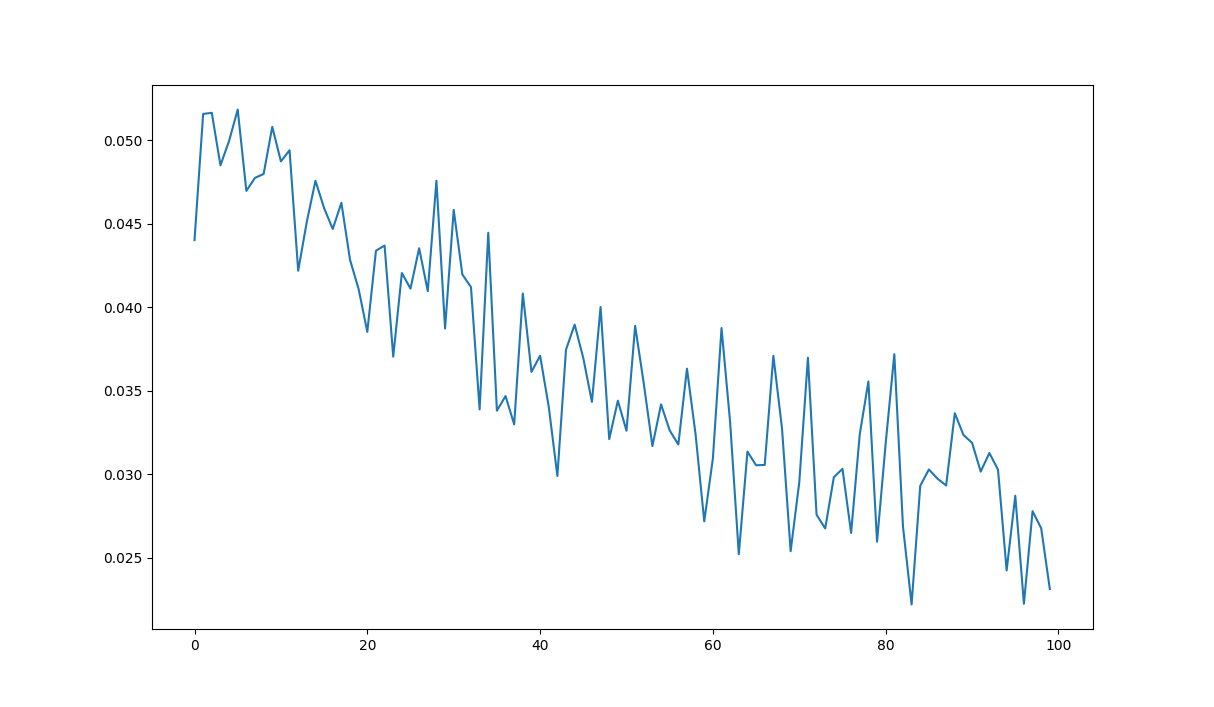
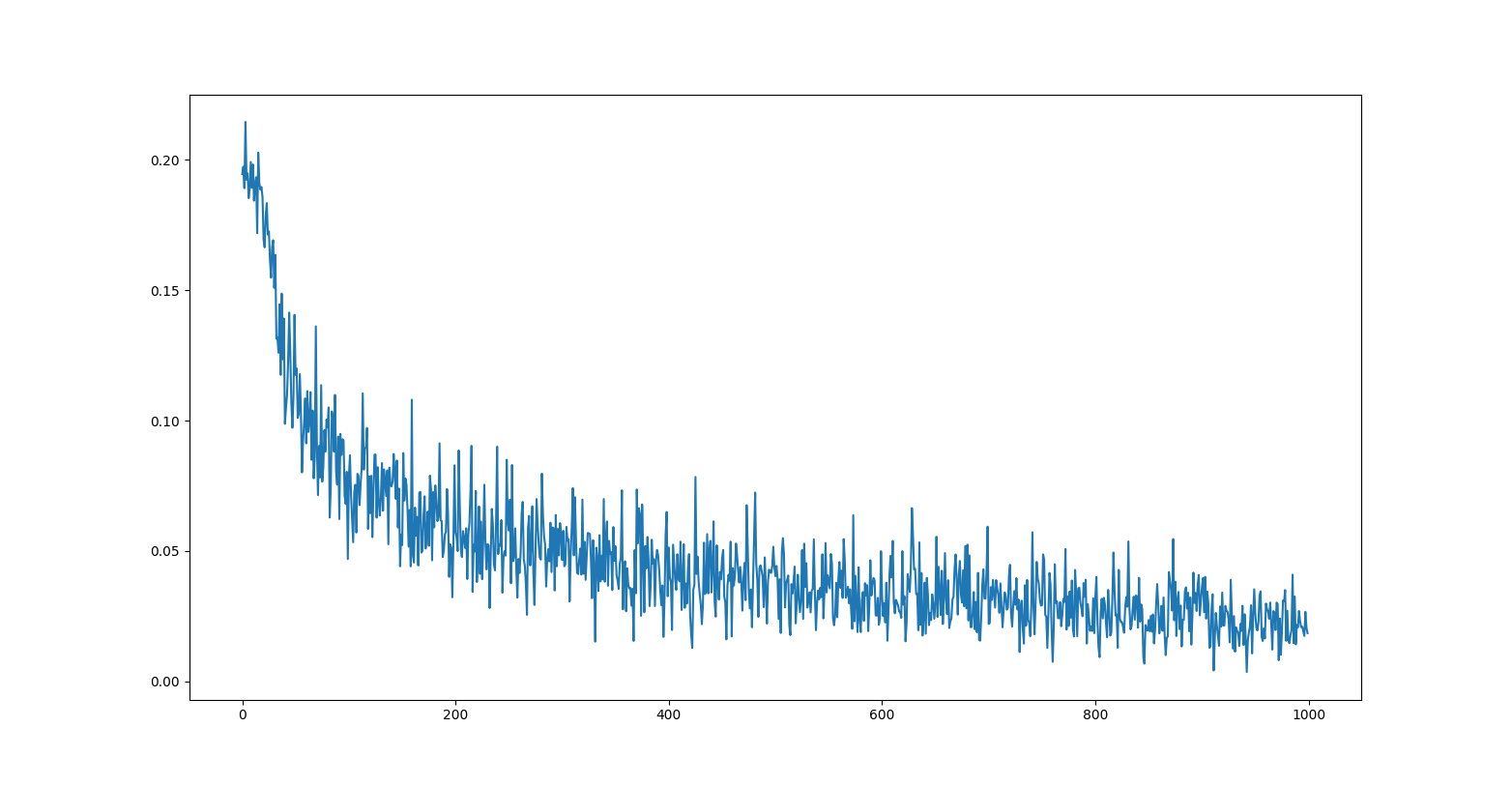
As the input data is random I expect for the network to learn nothing(i.e., get random error values).
The problem that I have is that the loss quickly converges to 0.5. The weights of the different layers of the network also converge to stable values.
...
tensor(0.5000, grad_fn=<MeanBackward1>)
tensor(0.5000, grad_fn=<MeanBackward1>)
tensor(0.5000, grad_fn=<MeanBackward1>)
...
The same happens when using real data(non random data).
Why is this happening?