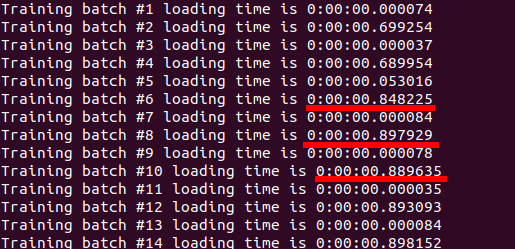
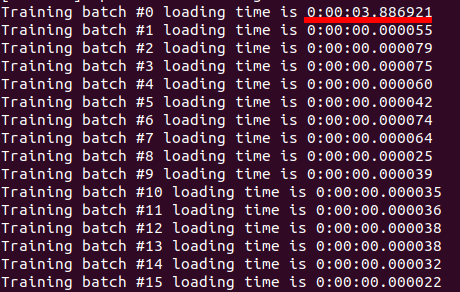
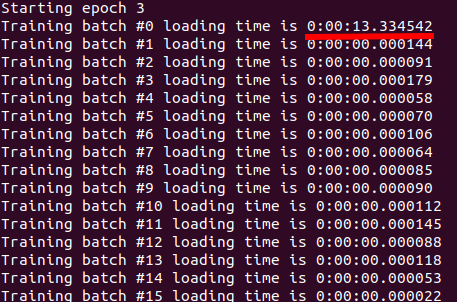
I am using a custom dataset and used custom data.Dataset class for loading it.
class MyDataset(data.Dataset):
def __init__(self, datasets, transform=None, target_transform=None):
self.datasets = datasets
self.transform = transform
def __len__(self):
return len(self.datasets)
def __getitem__(self, index):
image = Image.open(os.path.join(self.datasets[index][0]))
if self.transform:
image = self.transform(image)
return image, torch.tensor(self.datasets[index][1], dtype=torch.long)
When I started training on my 4 GPU machine, unlike the mentioned in Pytorch documentation, I found that DistributedDataParallel is slower than DataParallel!
I reviewed my code carefully and tried different configurations and batch sizes (especially the DataLoader num_workers) to see what makes DistributedDataParallel runs faster than DataParallel as expected, but nothing worked.
The only change I did that made DistributedDataParallel faster is loading the whole dataset into memory during initialization!
class Inmemory_Dataset(data.Dataset):
def __init__(self, datasets, transform=None, target_transform=None):
self.datasets = datasets
transform = transform
image_list = []
target_list = []
for i, data in enumerate(datasets):
image = Image.open(os.path.join(data[0]))
if transform:
image = transform(image)
image_list.append(image.numpy())
target_list.append(data[1])
self.images = torch.tensor(image_list)
self.targets = torch.tensor(target_list, dtype=torch.long)
def __len__(self):
return len(self.datasets)
def __getitem__(self, index):
return self.images[index], self.targets[index]
After this change, DistributedDataParallel became 30% faster. but I do not think this is how it should be. Because what if my dataset does not fit into memory?
Below I highlight the main parts where I setup the use for both DataParallel and DistributedDataParallel. Notice that the overall effictive batch size is the same in both cases.
DataParallel:
batch_size = 100
if torch.cuda.device_count() > 1:
print("Using DataParallel...")
model = nn.DataParallel(model)
batch_size = batch_size * torch.cuda.device_count()
DistributedDataParallel:
def train(gpu, args):
# print(args)
rank = args.nr * args.gpus + gpu
dist.init_process_group(backend='nccl', init_method='env://', world_size=args.world_size, rank=rank)
batch_size = 100
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
train_sampler = torch.utils.data.distributed.DistributedSampler(training_dataset,
num_replicas=args.world_size,
rank=rank)
training_dataloader = torch.utils.data.DataLoader(
dataset=training_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=1,
sampler=train_sampler,
pin_memory=True)